0x00:前言
PE文件可以说是在逆向的各个领域都有涉及,特别是病毒领域,如果你是一名病毒制造者,那你肯定是对PE文件有详细的了解,那么这里我就详细介绍一下PE文件,最后我们用C来写一个PE格式解析器。
0x01:PE格式
总体介绍
首先说明一个概念,可执行文件(Executable File)是指可以由操作系统直接加载执行的文件,在Windows操作系统中可执行文件就是PE文件结构,在Linux下则是ELF文件,我们这里只讨论Windows下的PE文件,要了解PE文件,首先要知道PE格式,那么什么是PE格式呢,既然是一个格式,那肯定是我们都需要遵循的定理,下面这张图就是PE文件格式的图片(来自看雪),非常大一张图片,其实PE格式就是各种结构体的结合,Windows下PE文件的各种结构体在WinNT.h这个头文件中,可以在VS中查询。

PE文件整体结构
PE结构可以大致分为:
- DOS部分
- PE文件头
- 节表(块表)
- 节数据(块数据)
- 调试信息
PE指纹
为了更加直观的描述我们用16进制编辑器直接将一个exe文件载入,分析其结构,首先我们需要清楚的概念是PE指纹,也就是判断一个文件是否是PE文件的依据,首先是根据文件的前两个字节是否为4D 5A,也就是’MZ’,然后看第四排四个字节指向的地址00 00 00 f8是否为50 45,也就是’PE’,满足这两个条件也就满足了PE文件的格式,简称PE指纹,在后面制作解析器的时候会通过它来判断是否为一个有效的PE文件。
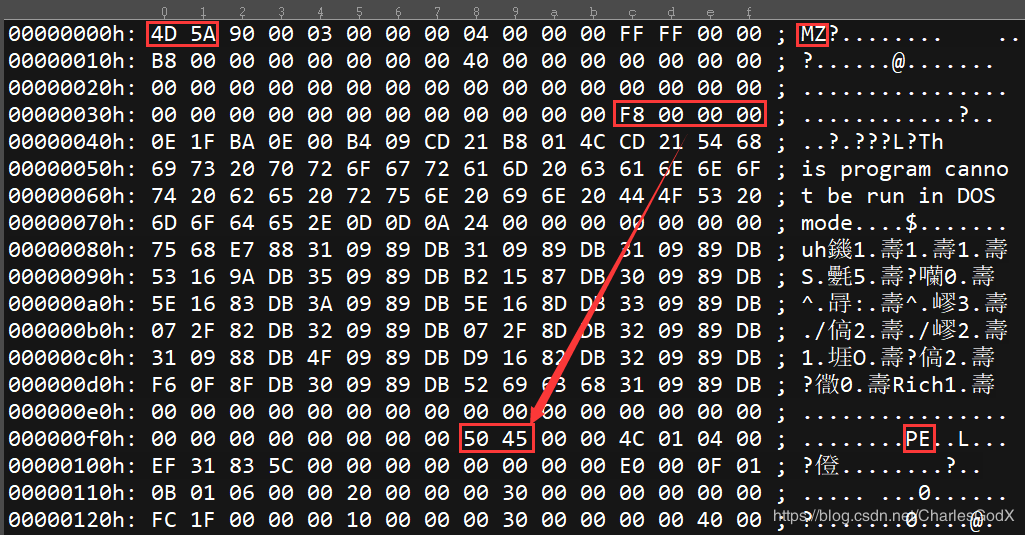
DOS部分
DOS部分主要是为了兼容以前的DOS系统,DOS部分可以分为DOS MZ文件头(IMAGE_DOS_HEADER)和DOS块(DOS Stub)组成,PE文件的第一个字节位于一个传统的MS-DOS头部,称作IMAGE_DOS_HEADER,其结构如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21typedef struct _IMAGE_DOS_HEADER { // DOS .EXE header
WORD e_magic; // Magic number
WORD e_cblp; // Bytes on last page of file
WORD e_cp; // Pages in file
WORD e_crlc; // Relocations
WORD e_cparhdr; // Size of header in paragraphs
WORD e_minalloc; // Minimum extra paragraphs needed
WORD e_maxalloc; // Maximum extra paragraphs needed
WORD e_ss; // Initial (relative) SS value
WORD e_sp; // Initial SP value
WORD e_csum; // Checksum
WORD e_ip; // Initial IP value
WORD e_cs; // Initial (relative) CS value
WORD e_lfarlc; // File address of relocation table
WORD e_ovno; // Overlay number
WORD e_res[4]; // Reserved words
WORD e_oemid; // OEM identifier (for e_oeminfo)
WORD e_oeminfo; // OEM information; e_oemid specific
WORD e_res2[10]; // Reserved words
LONG e_lfanew; // File address of new exe header
} IMAGE_DOS_HEADER, *PIMAGE_DOS_HEADER;
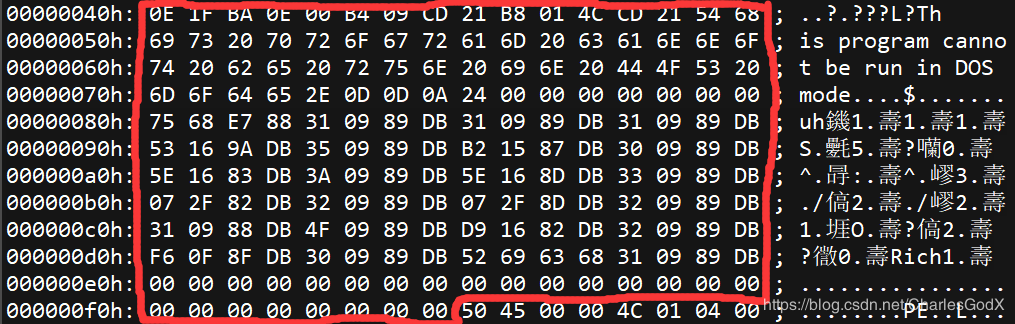
DOS部分我们需要熟悉的是e_magic成员和e_lfanew成员,前者是标识PE指纹的一部分,后者则是寻找PE文件头的部分,除了这两个成员,其他成员全部用0填充都不会影响程序正常运行,所以我们不需要过多的对其他部分深究,DOS部分在16进制编辑器中看就是下图的部分:

我们可以看到e_lfanew指向PE文件头,我们可以通过它来寻找PE文件头,而DOS块的部分自然就是PE文件头和DOS MZ文件头中间的部分,这部分是由链接器所写入的,可以随意进行修改,并不影响程序的运行:
PE文件头
PE文件头由PE文件头标志,标准PE头,扩展PE头三部分组成。PE文件头标志自然是50 40 00 00,也就是’PE’,我们从结构体的角度看一下PE文件头的详细信息1
2
3
4
5typedef struct _IMAGE_NT_HEADERS {
DWORD Signature; //PE文件头标志 => 4字节
IMAGE_FILE_HEADER FileHeader; //标准PE头 => 20字节
IMAGE_OPTIONAL_HEADER32 OptionalHeader; //扩展PE头 => 32位下224字节(0xE0) 64位下240字节(0xF0)
} IMAGE_NT_HEADERS32, *PIMAGE_NT_HEADERS32;
标准PE头结构如下,有20个字节,我们可以从PE文件头标志后20个字节找到它1
2
3
4
5
6
7
8
9typedef struct _IMAGE_FILE_HEADER {
WORD Machine; //可以运行在什么平台上 任意:0 ,Intel 386以及后续:14C x64:8664
WORD NumberOfSections; //节的数量
DWORD TimeDateStamp; //编译器填写的时间戳
DWORD PointerToSymbolTable; //调试相关
DWORD NumberOfSymbols; //调试相关
WORD SizeOfOptionalHeader; //标识扩展PE头大小
WORD Characteristics; //文件属性 => 16进制转换为2进制根据哪些位有1,可以查看相关属性
} IMAGE_FILE_HEADER, *PIMAGE_FILE_HEADER;
扩展PE头在32位和64位系统上大小是不同的,在32位系统上有224个字节,16进制就是0xE0,结构如下,重要的属性我都有标注1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42typedef struct _IMAGE_OPTIONAL_HEADER {
//
// Standard fields.
//
WORD Magic; //PE32: 10B PE64: 20B
BYTE MajorLinkerVersion;
BYTE MinorLinkerVersion;
DWORD SizeOfCode; //所有含有代码的区块的大小 编译器填入 没用(可改)
DWORD SizeOfInitializedData; //所有初始化数据区块的大小 编译器填入 没用(可改)
DWORD SizeOfUninitializedData; //所有含未初始化数据区块的大小 编译器填入 没用(可改)
DWORD AddressOfEntryPoint; //程序入口RVA
DWORD BaseOfCode; //代码区块起始RVA
DWORD BaseOfData; //数据区块起始RVA
//
// NT additional fields.
//
DWORD ImageBase; //内存镜像基址(程序默认载入基地址)
DWORD SectionAlignment; //内存中对齐大小
DWORD FileAlignment; //文件中对齐大小(提高程序运行效率)
WORD MajorOperatingSystemVersion;
WORD MinorOperatingSystemVersion;
WORD MajorImageVersion;
WORD MinorImageVersion;
WORD MajorSubsystemVersion;
WORD MinorSubsystemVersion;
DWORD Win32VersionValue;
DWORD SizeOfImage; //内存中整个PE文件的映射的尺寸,可比实际值大,必须是SectionAlignment的整数倍
DWORD SizeOfHeaders; //所有的头加上节表文件对齐之后的值
DWORD CheckSum; //映像校验和,一些系统.dll文件有要求,判断是否被修改
WORD Subsystem;
WORD DllCharacteristics; //文件特性,不是针对DLL文件的,16进制转换2进制可以根据属性对应的表格得到相应的属性
DWORD SizeOfStackReserve;
DWORD SizeOfStackCommit;
DWORD SizeOfHeapReserve;
DWORD SizeOfHeapCommit;
DWORD LoaderFlags;
DWORD NumberOfRvaAndSizes;
IMAGE_DATA_DIRECTORY DataDirectory[IMAGE_NUMBEROF_DIRECTORY_ENTRIES]; //数据目录表,结构体数组
} IMAGE_OPTIONAL_HEADER32, *PIMAGE_OPTIONAL_HEADER32;
程序中的扩展PE头大小在标准PE头中的显示如下图

扩展PE头在程序中显示如下,每一个属性可以通过偏移找到
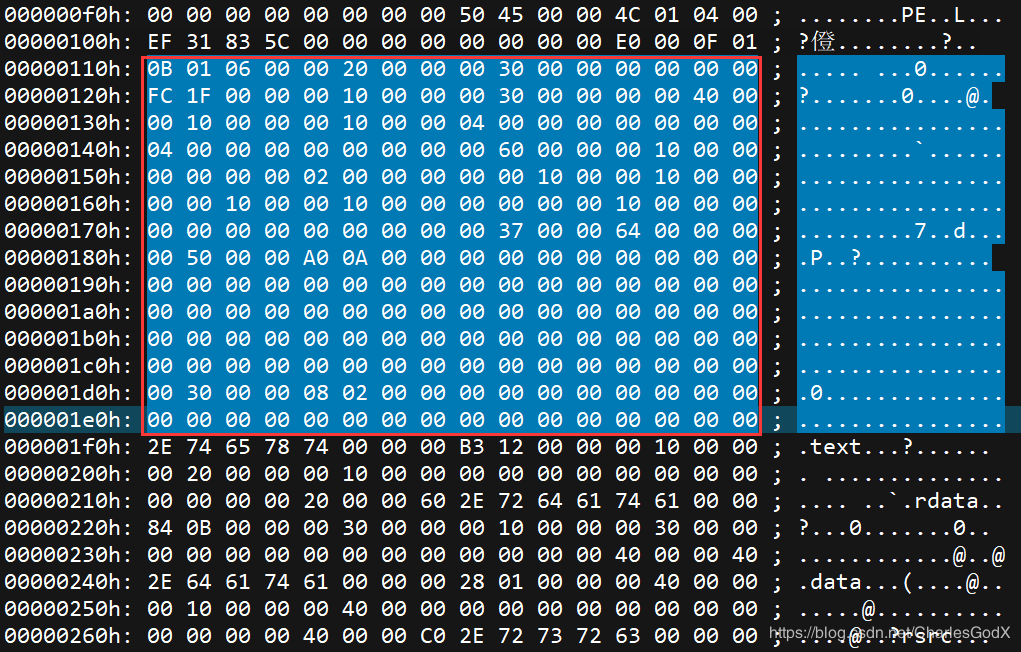
还需要知道的是,程序的真正入口点 = ImageBase + AddressOfEntryPoint
节表
节表的结构如下,整体为40个字节1
2
3
4
5
6
7
8
9
10
11
12
13
14
15typedef struct _IMAGE_SECTION_HEADER {
BYTE Name[IMAGE_SIZEOF_SHORT_NAME]; //ASCII字符串 可自定义 只截取8个字节
union { //该节在没有对齐之前的真实尺寸,该值可以不准确
DWORD PhysicalAddress;
DWORD VirtualSize;
} Misc;
DWORD VirtualAddress; //内存中的偏移地址
DWORD SizeOfRawData; //节在文件中对齐的尺寸
DWORD PointerToRawData; //节区在文件中的偏移
DWORD PointerToRelocations;
DWORD PointerToLinenumbers;
WORD NumberOfRelocations;
WORD NumberOfLinenumbers;
DWORD Characteristics; //节的属性
} IMAGE_SECTION_HEADER, *PIMAGE_SECTION_HEADER;
程序中显示如下

值得注意的是扩展PE头中的 FileAlignment 以及 SizeOfHeaders 这两个成员,SizeOfHeaders 表示所有的头加上节表文件对齐之后的值,对齐的大小参考的就是 FileAlignment 成员,如果所有的头加上节表的大小为320,FileAlignment 为 200,那么 SizeOfHeaders 大小就为 400,因为是根据FileAlignment 对齐的,这种对齐虽然牺牲了空间,但是可以提高程序运行效率,下图中的前面部分0x00100000就是程序在内存中对齐的大小,也就是程序运行起来时对齐的大小,0x00000400是程序在文件中的对齐大小,也就是没有运行时对齐的大小,需要清楚的是,PE程序在运行时内存中的对齐值和没有运行时的对齐值可能是截然不同的,了解这一点这对我们后面写PE解析器有帮助。

导入表
导出表(Import Table)和导入表是靠 IMAGE_DATA_DIRECTORY 这个结构体数组来寻找的,IMAGE_DATA_DIRECTORY 的结构如下1
2
3
4typedef struct _IMAGE_DATA_DIRECTORY {
DWORD VirtualAddress;
DWORD Size;
} IMAGE_DATA_DIRECTORY, *PIMAGE_DATA_DIRECTORY;
在程序中查找导出表如下图所示,因为结构体数组中每一个结构体大小为 16 位,又是扩展PE头中的最后一个成员,所以我们从节表段向上推 8 行即为我们的结构体数组开头,前 8 位是导出表的内容,因为是一个exe文件,这里刚好就没有导出表只有导入表,可以看到导入表RVA地址是0x00003700的位置
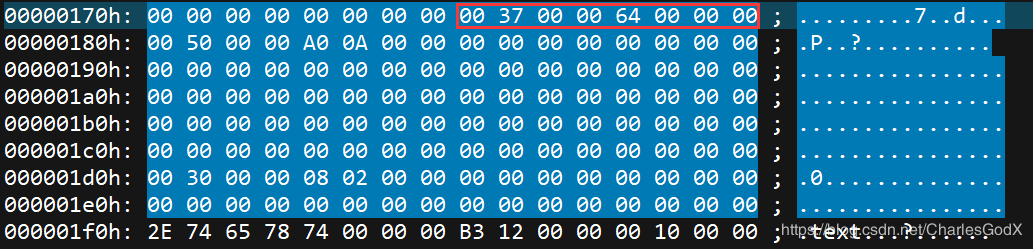
导入表的结构如下1
2
3
4
5
6
7
8
9
10
11
12
13
14
15typedef struct _IMAGE_IMPORT_DESCRIPTOR {
union {
DWORD Characteristics; // 0 for terminating null import descriptor
DWORD OriginalFirstThunk; // RVA 指向 INT (PIMAGE_THUNK_DATA结构数组)
} DUMMYUNIONNAME;
DWORD TimeDateStamp; // 0 if not bound,
// -1 if bound, and real date\time stamp
// in IMAGE_DIRECTORY_ENTRY_BOUND_IMPORT (new BIND)
// O.W. date/time stamp of DLL bound to (Old BIND)
DWORD ForwarderChain; // -1 if no forwarders
DWORD Name; //RVA指向dll名字,以0结尾
DWORD FirstThunk; // RVA 指向 IAT (PIMAGE_THUNK_DATA结构数组)
} IMAGE_IMPORT_DESCRIPTOR;
typedef IMAGE_IMPORT_DESCRIPTOR UNALIGNED *PIMAGE_IMPORT_DESCRIPTOR;
可以看到,OriginalFirstThunk 和 FirstThunk 指向的内容分别是 INT 和 IAT ,但实际上 INT 和 IAT 的内容是一样的,所以他们指向的内容是一样的,只是方式不同而已,下图可以完美的解释
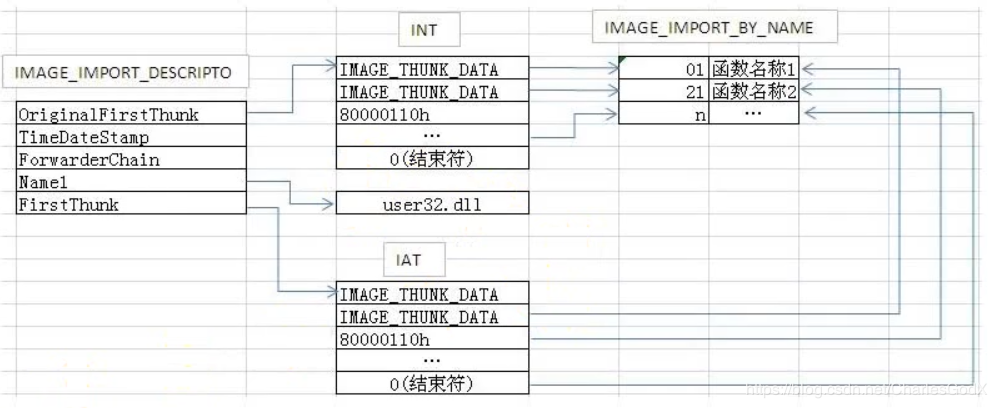
但是上图只是PE文件加载前的情况,PE文件一旦运行起来,就会变成下图的情况
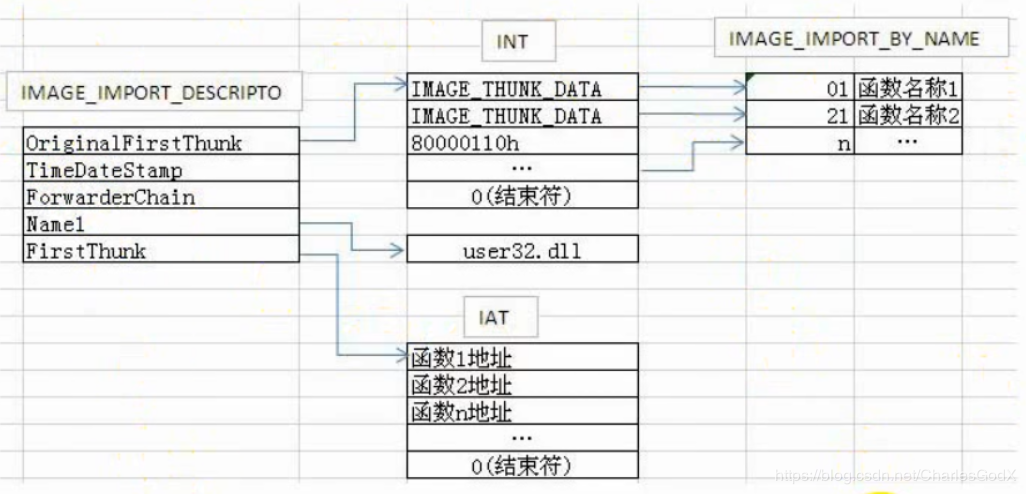
我们还需要了解的结构体是 IMAGE_THUNK_DATA 和 IMAGE_IMPORT_BY_NAME 结构如下
1 | typedef struct _IMAGE_IMPORT_BY_NAME { |
其实他们的作用很明显,就是用来寻找当前的模块依赖哪些函数,可以用这几个结构体求到依赖函数的名字。
导出表
导出表(Export Table)一般是DLL文件用的比较多,exe文件很少有导出表,导出表的数据结构如下1
2
3
4
5
6
7
8
9
10
11
12
13typedef struct _IMAGE_EXPORT_DIRECTORY {
DWORD Characteristics;
DWORD TimeDateStamp;
WORD MajorVersion;
WORD MinorVersion;
DWORD Name; // 指针指向该导出表文件名字符串
DWORD Base; // 导出函数起始序号
DWORD NumberOfFunctions; // 所有导出函数的个数
DWORD NumberOfNames; // 以函数名字导出的函数个数
DWORD AddressOfFunctions; // 指针指向导出函数地址表RVA
DWORD AddressOfNames; // 指针指向导出函数名称表RVA
DWORD AddressOfNameOrdinals; // 指针指向导出函数序号表RVA
} IMAGE_EXPORT_DIRECTORY, *PIMAGE_EXPORT_DIRECTORY;
可以看到导出表里面最后还有三个表,这三个表可以让我们找到函数真正的地址,在编写PE格式解析器的时候可以用到,AddressOfFunctions 是函数地址表,指向每个函数真正的地址,AddressOfNames 和 AddressOfNameOrdinals 分别是函数名称表和函数序号表,我们知道DLL文件有两种调用方式,一种是用名字,一种是用序号,通过这两个表可以用来寻找函数在 AddressOfFunctions 表中真正的地址。
重定位表
当PE文件被装载到虚拟内存的另一个地址中的时候,也就是载入时不将默认的值作为基地址载入,链接器登记的哪个地址是错误的,需要我们用重定位表来调整,重定位表在数据目录项的第 6 个结构,结构如下1
2
3
4
5
6typedef struct _IMAGE_BASE_RELOCATION {
DWORD VirtualAddress; // 重定位数据的开始 RVA 地址
DWORD SizeOfBlock; // 重定位块的长度
// WORD TypeOffset[1]; // 重定位项数组
} IMAGE_BASE_RELOCATION;
typedef IMAGE_BASE_RELOCATION UNALIGNED * PIMAGE_BASE_RELOCATION;
重定位表有许多个,以八个字节的 0 结尾
0x02:PE解析器编写
这里放一个由C写的简易的PE分析工具,写的比较简单,主要是为了熟悉PE结构,代码我也传到了GitHub上面,需要的可以自行下载。
下载链接
https://github.com/ThunderJie/Code/tree/master/PE1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
DWORD RVAOffset(PIMAGE_NT_HEADERS pNtHeader, DWORD Rva)
{
PIMAGE_SECTION_HEADER pSectionHeader = (PIMAGE_SECTION_HEADER)IMAGE_FIRST_SECTION(pNtHeader);
for (int i = 0; i < pNtHeader->FileHeader.NumberOfSections; i++)
{
DWORD SectionBeginRva = pSectionHeader[i].VirtualAddress;
DWORD SectionEndRva = pSectionHeader[i].VirtualAddress + pSectionHeader[i].SizeOfRawData;
if (Rva >= SectionBeginRva && Rva <= SectionEndRva)
{
DWORD Temp = Rva - SectionBeginRva;
DWORD Rwa = Temp + pSectionHeader[i].PointerToRawData;
return Rwa;
}
}
}
int main(int argc, char* argv[])
{
HANDLE hFile;
HANDLE hMapping;
LPVOID ImageBase;
char szFilePath[MAX_PATH];
OPENFILENAME ofn;//定义结构,调用打开对话框选择要分析的文件及其保存路径
PIMAGE_DOS_HEADER pDH = NULL;//指向IMAGE_DOS结构的指针
PIMAGE_NT_HEADERS pNtH = NULL;//指向IMAGE_NT结构的指针
PIMAGE_FILE_HEADER pFH = NULL;//指向IMAGE_FILE结构的指针
PIMAGE_OPTIONAL_HEADER pOH = NULL;//指向IMAGE_OPTIONALE结构的指针
memset(szFilePath, 0, MAX_PATH);
memset(&ofn, 0, sizeof(ofn));
ofn.lStructSize = sizeof(ofn);
ofn.hwndOwner = NULL;
ofn.hInstance = GetModuleHandle(NULL);
ofn.nMaxFile = MAX_PATH;
ofn.lpstrInitialDir = ".";
ofn.lpstrFile = szFilePath;
ofn.lpstrTitle = "choose a PE file --by Thunder_J";
ofn.Flags = OFN_PATHMUSTEXIST | OFN_FILEMUSTEXIST | OFN_HIDEREADONLY;
ofn.lpstrFilter = "*.*\0*.*\0";
if (!GetOpenFileName(&ofn))
{
printf("打开文件错误:%d\n", GetLastError());
return 0;
}
hFile = CreateFile(szFilePath, GENERIC_READ, FILE_SHARE_READ, NULL, OPEN_EXISTING, FILE_ATTRIBUTE_NORMAL, 0);
if (!hFile)
{
MessageBox(NULL, "打开文件错误", NULL, MB_OK);
return 0;
}
hMapping = CreateFileMapping(hFile, NULL, PAGE_READONLY, 0, 0, NULL);
if (!hMapping)
{
printf("创建映射错误:%d", GetLastError());
CloseHandle(hFile);
return 0;
}
ImageBase = MapViewOfFile(hMapping, FILE_MAP_READ, 0, 0, 0);
if (!ImageBase)
{
printf("文件映射错误:%d", GetLastError());
CloseHandle(hMapping);
CloseHandle(hFile);
return 0;
}
/************************************************************************/
/* PE头的判断 */
/************************************************************************/
if (!ImageBase) //判断映像地址
{
printf("Not a valid PE file 1!\n");
CloseHandle(hMapping);
CloseHandle(hFile);
return 0;
}
printf("--------------------PEheader------------------------\n");
pDH = (PIMAGE_DOS_HEADER)ImageBase;
if (pDH->e_magic!=IMAGE_DOS_SIGNATURE) //判断是否为MZ
{
printf("Not a valid PE file 2!\n");
CloseHandle(hMapping);
CloseHandle(hFile);
return 0;
}
pNtH = (PIMAGE_NT_HEADERS)((DWORD)pDH + pDH->e_lfanew); //判断是否为PE格式
if (pNtH->Signature!=IMAGE_NT_SIGNATURE)
{
printf("Not a valid PE file 3!\n");
CloseHandle(hMapping);
CloseHandle(hFile);
return 0;
}
printf("PE e_lfanew is: 0x%x\n", pNtH);
/************************************************************************/
/* FileHeader */
/************************************************************************/
pFH = &pNtH->FileHeader;
printf("-----------------FileHeader------------------------\n");
printf("NumberOfSections: %d\n", pFH->NumberOfSections);
printf("SizeOfOptionalHeader: %d\n", pFH->SizeOfOptionalHeader);
/************************************************************************/
/* OptionalHeader */
/************************************************************************/
pOH = &pNtH->OptionalHeader;
printf("-----------------OptionalHeader---------------------\n");
printf("SizeOfCode:0x%08x\n", pOH->SizeOfCode);
printf("AddressOfEntryPoint: 0x%08X\n", pOH->AddressOfEntryPoint);
printf("ImageBase is 0x%x\n", ImageBase);
printf("SectionAlignment: 0x%08x\n", pOH->SectionAlignment);
printf("FileAlignment: 0x%08x\n", pOH->FileAlignment);
printf("SizeOfImage: 0x%08x\n", pOH->SizeOfImage);
printf("SizeOfHeaders: 0x%08x\n", pOH->SizeOfHeaders);
printf("NumberOfRvaAndSizes: 0x%08x\n", pOH->NumberOfRvaAndSizes);
/************************************************************************/
/* SectionTable */
/************************************************************************/
int SectionNumber = 0;
DWORD SectionHeaderOffset = (DWORD)pNtH + 24 + (DWORD)pFH->SizeOfOptionalHeader; //节表位置的计算
printf("--------------------SectionTable---------------------\n");
for (SectionNumber; SectionNumber < pFH->NumberOfSections;SectionNumber++)
{
PIMAGE_SECTION_HEADER pSh = (PIMAGE_SECTION_HEADER)(SectionHeaderOffset + 40 * SectionNumber);
printf("%d 's Name is %s\n", SectionNumber + 1, pSh->Name);
printf("VirtualAddress: 0x%08X\n", (DWORD)pSh->VirtualAddress);
printf("SizeOfRawData: 0x%08X\n", (DWORD)pSh->SizeOfRawData);
printf("PointerToRawData: 0x%08X\n", (DWORD)pSh->PointerToRawData);
}
/************************************************************************/
/* ExportTable */
/************************************************************************/
printf("--------------------ExportTable----------------------\n");
DWORD Export_table_offset = RVAOffset(pNtH, (DWORD)pNtH->OptionalHeader.DataDirectory[IMAGE_DIRECTORY_ENTRY_EXPORT].VirtualAddress);
PIMAGE_EXPORT_DIRECTORY pExportDirectory = (PIMAGE_EXPORT_DIRECTORY)((DWORD)ImageBase + Export_table_offset);
DWORD EXport_table_offset_Name = (DWORD)ImageBase + RVAOffset(pNtH, pExportDirectory->Name);
DWORD * pNameOfAddress = (DWORD *)((DWORD)ImageBase + RVAOffset(pNtH, pExportDirectory->AddressOfNames));
DWORD * pFunctionOfAdress = (DWORD *)((DWORD)ImageBase + RVAOffset(pNtH, pExportDirectory->AddressOfFunctions));
WORD * pNameOrdinalOfAddress = (WORD *)((DWORD)ImageBase + RVAOffset(pNtH, pExportDirectory->AddressOfNameOrdinals));
printf("Name:%s\n", EXport_table_offset_Name);
printf("NameOfAddress:%08X\n", RVAOffset(pNtH, pExportDirectory->AddressOfNames));
printf("FunctionOfAdress:%08X\n", RVAOffset(pNtH, pExportDirectory->AddressOfFunctions));
printf("NameOrdinalOfAddress:%08X\n", RVAOffset(pNtH, pExportDirectory->AddressOfNameOrdinals));
if (pExportDirectory->NumberOfFunctions == 0)
{
puts("!!!!!!!!!!!!!!!!!NO EXPORT!!!!!!!!!!!!!!!!!!!!!");
if (hFile != INVALID_HANDLE_VALUE)
{
CloseHandle(hFile);
}
if (hMapping != NULL)
{
CloseHandle(hMapping);
}
if (ImageBase != NULL)
{
UnmapViewOfFile(ImageBase);
}
}
printf("NumberOfNames:%d\n", pExportDirectory->NumberOfNames);
printf("NumberOfFunctions:%d\n", pExportDirectory->NumberOfFunctions);
/************************************************************************/
/* ImportTable */
/************************************************************************/
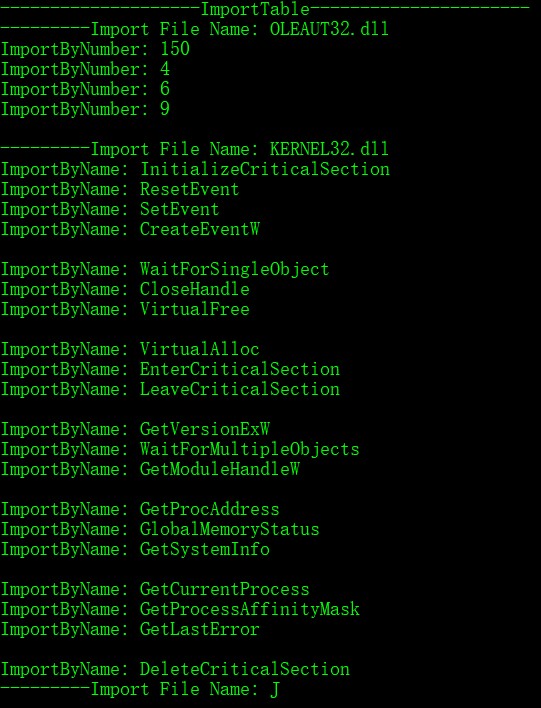
printf("--------------------ImportTable----------------------\n");
int cont = 0;
do
{
DWORD dwImportOffset = RVAOffset(pNtH, pNtH->OptionalHeader.DataDirectory[IMAGE_DIRECTORY_ENTRY_IMPORT].VirtualAddress);
dwImportOffset = dwImportOffset + cont;
PIMAGE_IMPORT_DESCRIPTOR pImport = (PIMAGE_IMPORT_DESCRIPTOR)((DWORD)ImageBase + dwImportOffset);
if (pImport->OriginalFirstThunk == 0 && pImport->TimeDateStamp == 0 && pImport->ForwarderChain == 0 && pImport->Name == 0 && pImport->FirstThunk == 0)
break;
DWORD dwOriginalFirstThunk = (DWORD)ImageBase + RVAOffset(pNtH, pImport->OriginalFirstThunk);
DWORD dwFirstThunk = (DWORD)ImageBase + RVAOffset(pNtH, pImport->FirstThunk);
DWORD dwName = (DWORD)ImageBase + RVAOffset(pNtH, pImport->Name);
printf("---------Import File Name: %s\n", dwName);
if (dwOriginalFirstThunk == 0x00000000)
{
dwOriginalFirstThunk = dwFirstThunk;
}
DWORD* pdwTrunkData = (DWORD*)dwOriginalFirstThunk;
int n = 0, x = 0;
while (pdwTrunkData[n] != 0)
{
DWORD TrunkData = pdwTrunkData[n];
if (TrunkData < IMAGE_ORDINAL_FLAG32)//名字导入
{
PIMAGE_IMPORT_BY_NAME pInportByName = (PIMAGE_IMPORT_BY_NAME)((DWORD)ImageBase + RVAOffset(pNtH, TrunkData));
printf("ImportByName: %s\n", pInportByName->Name);
}
else
{
DWORD FunNumber = (DWORD)(TrunkData - IMAGE_ORDINAL_FLAG32);
printf("ImportByNumber: %-4d \n", FunNumber);
}
if (x != 0 && x % 3 == 0) printf("\n");
n++;
x++;
}
cont = cont + 40;
} while (1);
{
if (ImageBase)
{
UnmapViewOfFile(ImageBase);
}
if (hMapping)
{
CloseHandle(hMapping);
}
if (hFile != INVALID_HANDLE_VALUE)
{
CloseHandle(hFile);
}
return 0;
}
}
运行效果
节表以及之前信息
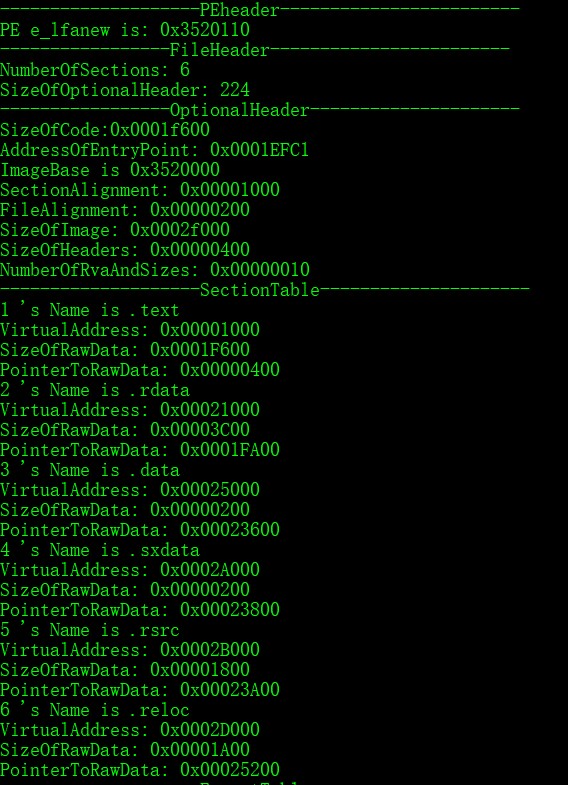
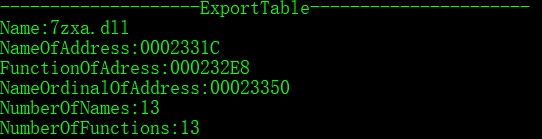
导出表
导入表
0x03:总结
这个PE解析器虽然简单,但是自己写了之后对PE的理解和之前截然不同,后续可以对这个解析器进行各种优化,判断是否有壳之类的功能可以添加上去。