进程与线程
线程和进程的概念不用多说大家肯定都比较熟悉,线程是具有能动性、执行力、独立性的代码块。进程 = 线程+资源。那么下面代码中你能区别普通函数和线程函数的区别么?我们知道普通的函数之间发生函数调用的时候,要进行压栈的一系列操作,然后调用,它需要依赖程序上下文的环境。而线程函数则是自己提供一套上下文环境,使其更加具有独立性的在处理器上执行。二者的区别也主要是上下文环境。
1 | void threadFunc(void *arg) |
我们再来说说进程,操作系统为每个进程提供了一个PCB,用于记录此进程相关的信息,所有进程的PCB形成了一张表,这就是进程表,我们自己写的操作系统中PCB的结构是不固定的,其大致内容有寄存器映像、栈、pid、进程状态、优先级、父进程等,为了实现它,我们先创建thread目录,然后创建thread.c和.h文件,下面是PCB的结构,位于.h文件中
1 | /* 进程或线程的pcb,程序控制块 */ |
我们的线程是在内核中实现的,所以申请PCB结构的时候是从内核池进行操作的,下面看看初始化的内容,主要内容是给PCB的各字段赋值
1 | /* 初始化线程基本信息 */ |
然后用thread_create初始化栈thread_stack,其中减去的操作主要是为了以后预留保存现场的空间
1 | /* 初始化线程栈thread_stack,将待执行的函数和参数放到thread_stack中相应的位置 */ |
上面的function即使线程所执行的函数,这个函数并不是用call去调用,我们用的是ret指令进行调用,CPU执行哪条指令是通过EIP的指向来决定的,而ret指令在返回的时候,当前的栈顶就会被当做是返回地址。也就是说,我们可以把某个函数的地址放在栈顶,通过这个函数来执行线程函数。那么在ret返回的时候,就会进入我们指定的函数当中,这个函数就会来调用线程函数。下面就是启动线程的函数
1 | /* 由kernel_thread去执行function(func_arg) */ |
为了实验我们还需要在main.c中对thread_start进行调用
1 |
|
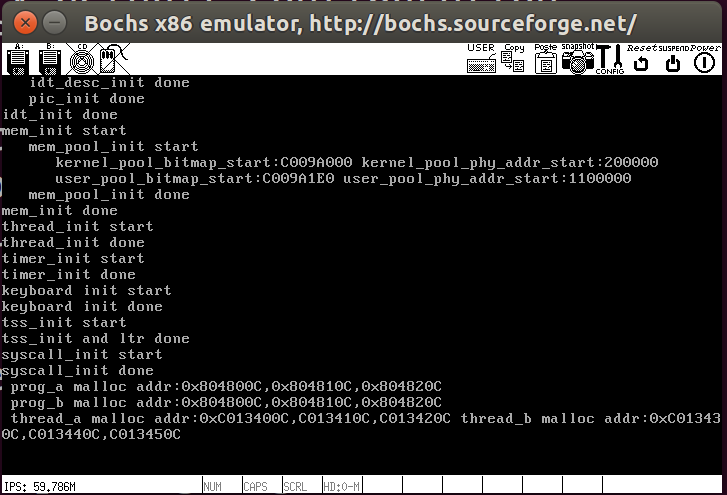
编译运行结果如下所示,测试成功
多线程调度
为了提高效率,实现多线程调度,我们需要用数据结构对内核线程结构进行维护,首先我们需要在lib/kernel目录下增加队列结构
1 |
|
多线程调度需要我们继续改进线程代码,我们用PCB中的general_tag字段作为节点链接所有PCB,其中还有一个ticks字段用于记录线程执行时间,ticks越大,优先级越高,时钟中断一次,ticks就会减一,当其为0的时候,调度器就会切换线程,选择另一个线程上处理器执行,然后打上TASK_RUNNING的标记,之后通过switch_to函数将新线程的寄存器环境恢复,这样新线程才得以执行,完整调度过程需要以下三步
- 时钟中断处理函数
- 调度器schedule
- 任务切换函数switch_to
调度器主要实现如下
1 | /* 实现任务调度 */ |
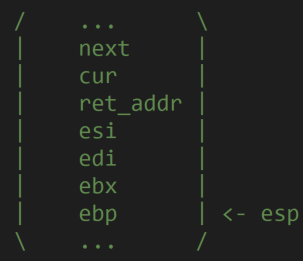
接下来是切换函数的实现,在thread/目录下创建switch.S,由两部分组成第一部分负责保存任务进入中断前的全部寄存器,第二部分负责保存esi、edi、ebx、ebp四个寄存器。堆栈图压栈之后的如下所示
代码如下所示
1 | [bits 32] |
修改makefie、printf等一些文件之后,最终能实现多线程的调度主函数main.c如下所示
1 |
|
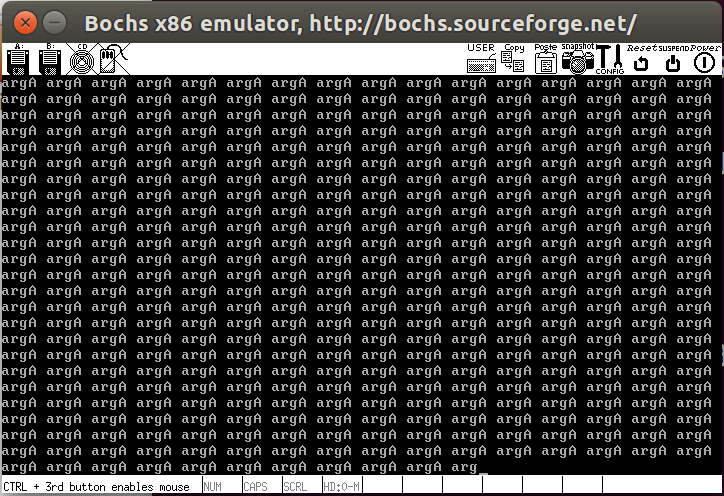
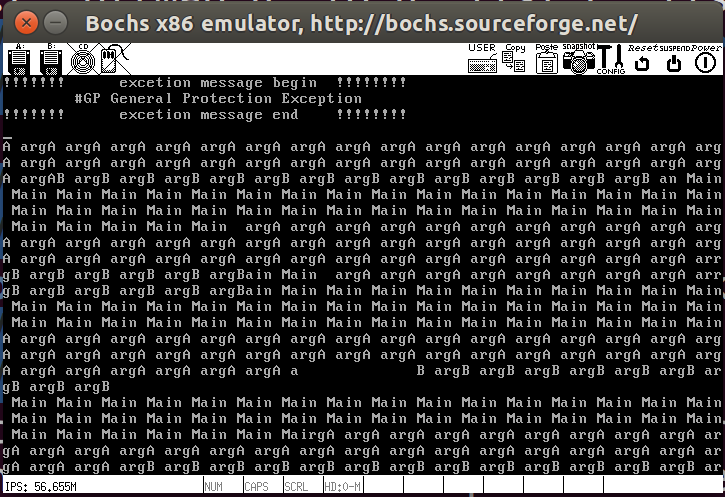
不过这里会引发GP异常,如下所示,可以用nm build/kernel.bin | grep thread_start查看线程函数地址,然后在线程函数下断点,再用show exitint打印中断信息,这样就可以观察异常处的寄存器信息,这里产生异常的原因是寄存器bx的值超过了段界限limit的值0x7fff
输入输出系统
同步机制-锁
思考之前代码的问题,字符打印问题主要出现在交界处无法打印正确,回忆put_str函数打印有三个步骤
- 获取光标值
- 将光标值转换为字节地址,在该地址处写入字符
- 更新光标值
在打印的时候,若线程A到了第二步,此时发生了时钟中断,那么线程B就会重新获取光标值,这样导致数据覆盖,所以我们需要保证公共资源显存只有一个线程访问,也就是需要保证原子性,我们需要在put_str函数中进行开关中断的操作,如下所示,后面对公共资源”光标寄存器”也需要这样进行原子操作避免GP异常,这样做可以正确的打印输出,但只能解决输出函数线程竞争的问题,如果其他地方也有这种竞争问题就需要我们用一种新的机制来解决,也就是锁的机制。
1 | [...] |
要进行线程同步,肯定要在需要同步的地方阻止线程的切换。这里主要通过信号量的机制对公共资源加锁,达到同步的目的。信号量的原理本身比较简单。通过P、V操作来表示信号量的增减,如下。
P操作,减少信号量:
- 判断信号量是否大于0
- 如果大于0, 将其减一
- 如果小于0,将当前线程阻塞
V操作,增加信号量:
- 将信号量的值加一
- 唤醒等待的线程
首先我们需要实现线程的阻塞与唤醒,阻塞通常是线程自己阻塞自己,唤醒通常是其他线程唤醒本线程。具体实现如下,在thread.c中进行修改
1 | /* 当前线程将自己阻塞,标志其状态为stat. */ |
信号量锁的结构如下,实现在thread/sync.c和.h,信号量仅仅是一个编程理念,实现功能即可
1 | /* 信号量结构 */ |
初始化就是给各个字段赋值
1 | /* 初始化信号量 */ |
P操作
1 | /* 信号量down操作 */ |
V操作
1 | /* 信号量的up操作 */ |
获取锁和释放锁
1 | /* 获取锁plock */ |
接下来需要对锁进行测试,我们需要对终端输出进行封装,基本上都是对锁的使用,没什么好说的
1 |
|
然后在init文件添加初始化函数并在main文件进行测试,只需要将put_str("...")修改为console_put_str("..."),测试结果如下
键盘获取输入输出
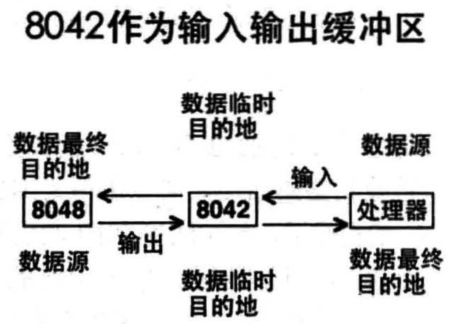
键盘的输入和输出主要是对8042和8048芯片的操作,这两芯片的数据在P456页开始有介绍,主要是对端口0x60的操作,其作为IO缓冲区,关系如下
我们将键盘的输入根据键盘扫描码(P462)进行转换,最终需要将其转换为我们键盘按下字符对应的ASCII码。其本质就是,键盘中断处理程序负责接收按键信息,也就是扫描码,然后就是对扫描码的处理,我们将用驱动程序对其进行实现,需要分两个阶段完成
- 如果是一些用于操作方面的控制键,比如shift,crtl等,就交给键盘驱动中完成
- 如果是一些用于字符方面的键,就直接交给字符处理程序完成即可
我们在device/keyboard.c和.h中实现,其中对于操作控制键和其他键配合按下的情况,比如crtl+a这种就需要定义一个变量判断之前是否已经按下crtl键,对于shift组合字符我们用的是二维数组保存,如shift+1显示的是 ! 字符
1 | /* 定义以下变量记录相应键是否按下的状态, |
后面的函数都是对通码、断码、组合键的一些处理
1 | /* 键盘中断处理程序 */ |
修改main函数对我们的输入进行测试
1 |
|
测试结果如下,可以实现大部分键盘的输入,但当使用小键盘中1~9的时候会显示未识别,不过这个问题不大
为了构建交互式的shell,我们需要实现一个缓冲区用来保存我们输入的指令,这里我们使用的是一个环形的缓冲区,既然是环形,就涉及到它的设计思路,我们使用的是生产者-消费者模型,具体实现在device目录下的ioqueue.c和.h文件中,其中队列结构如下所示
1 |
|
初始化io队列
1 | /* 初始化io队列ioq */ |
其他函数如下所示,其中比较关键的是ioq_getchar和ioq_putchar函数
1 | /* 返回pos在缓冲区中的下一个位置值 */ |
我们还需要修改interrupt.c文件,打开时钟中断和键盘中断,最后在main.c中修改测试代码如下
1 | [...] |
这里我一直按下的 t 键,可以看到线程A和B交替执行
用户进程
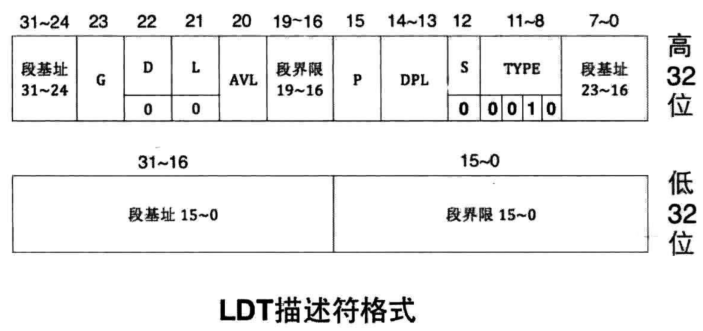
LDT
之前介绍GDT的时候提到过LDT,我们的操作系统本身不实现LDT,但其作用还是有必要了解的,LDT也叫局部描述符表。按照内存分段的方式,内存中的程序映像自然被分成了代码段、数据段等资源,这些资源属于程序私有部分,因此intel建议为每个程序单独赋予一个结构来存储其私有资源,这个结构就是LDT,因为是每个任务都有的,故其位置不固定,要找到它需要先像GDT那样注册,之后用选择子找到它。其格式如下,LDT中描述符的D位和L位固定为0,因为属于系统断描述符,因此S为0。描述符在S为0的前提下,若TYPE的值为0010,即表示描述符是LDT。与其配套的寄存器和指令即为LDTR和lldt "16位通用寄存器" 或 "16位内存单元":
TSS
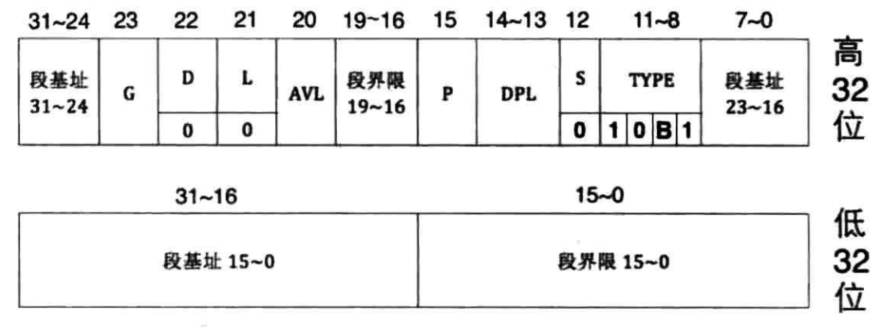
单核CPU想要实现多任务,唯一的方案就是多个任务共享同一个CPU,也就是让CPU在多个任务间轮转。TSS就是给每个任务”关联”的一个任务状态段,用它来关联任务。TSS(任务状态段)是由程序员来提供,CPU进行维护。程序员提供是指需要我们定义一个结构体,里面存放任务要用的寄存器数据。CPU维护是指切换任务时,CPU会自动把旧任务的数据存放的结构体变量中,然后将新任务的TSS数据加载到相应的寄存器中。
TSS和之前所说的段一样,本质上也是一片存储数据的内存区域,CPU用这块内存区域保存任务的最新状态。所以也需要一个描述符结构来表示它,这个描述符就是TSS描述符,它的结构如下,因为属于系统断描述符,因此S为0。描述符在S为0的前提下,若TYPE的值为10B1,B位表示Busy,为1表示繁忙,0表示空闲
其工作模式和LDT相似,由寄存器TR保存TSS的起始地址,使用前也需要进行注册,都是通过选择子来访问的,将TSS加载到TR的指令是ltr,格式如下
1 | ltr "16位通用寄存器" 或 "16位内存单元" |
任务切换的方式有”中断+任务门”、”call或jmp+任务门”、和iretd三种方式,这些方式都比较繁琐,对于Linux系统以及大部分x86系统而言,这样使用TSS效率太低,这一套标准需要我们在”应付”的前提下达到最高效率,我们这里主要效仿Linux系统的做法,Linux为了提高任务切换的速度,通过如下方式来进行任务切换:
一个CPU上的所有任务共享一个TSS,通过TR寄存器保存这个TSS,在使用ltr指令加载TSS之后,该TR寄存器永远指向同一个TSS,之后在进行任务切换的时候也不会重新加载TSS,只需要把TSS中的SS0和esp0更新为新任务的内核栈的段地址及栈指针。
接下来我们实现TSS,在kernel/global.h中我们增加一些描述符属性
1 | // ---------------- GDT描述符属性 ---------------- |
关键代码我们在userprog/tss.c中实现,首先根据tss结构构造如下结构体
1 | /* 任务状态段tss结构 */ |
初始化主要是效仿Linux中初始化ss0和esp0,然后将TSS描述符加载到全局描述符表中,因为GDT中第0个描述符不可用,第1个为代码段,第2个为数据段和栈,第3个为显存段,第4个就是我们的tss,故地址为0xc0000900+0x20
1 |
|
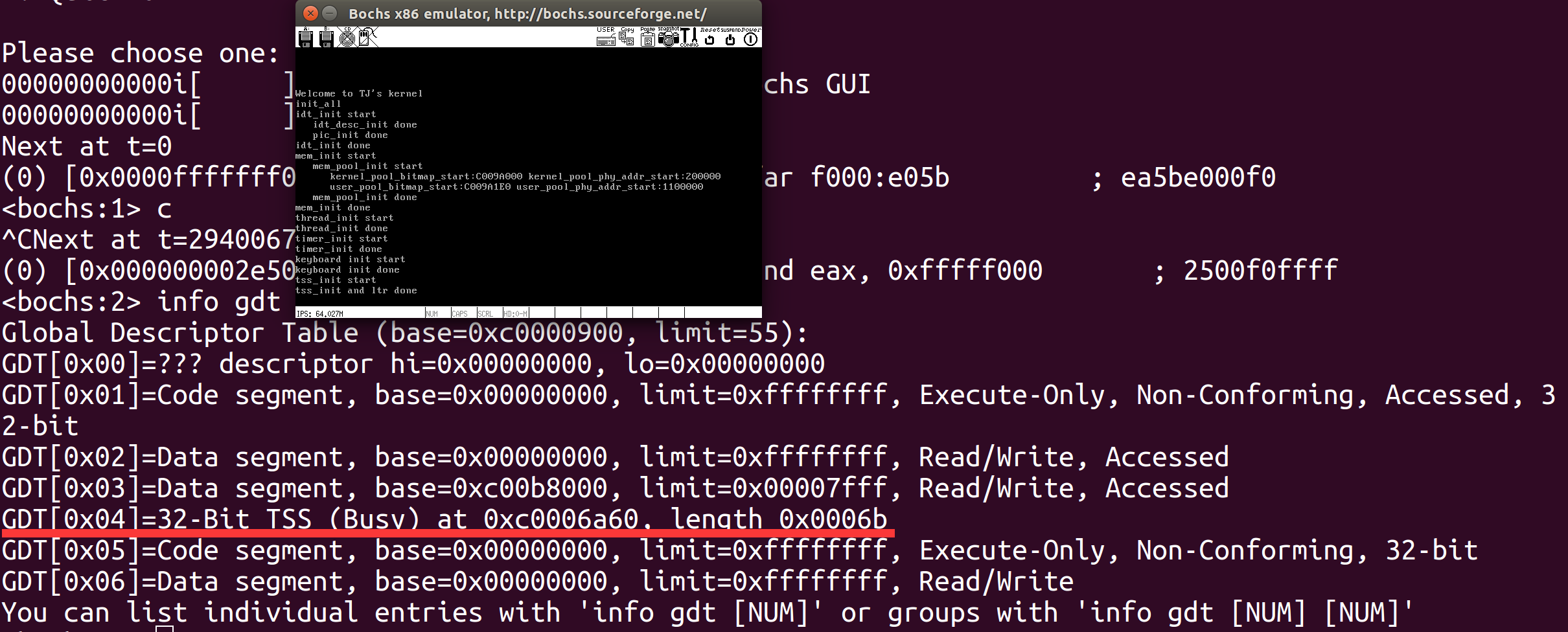
修改初始化函数之后,测试一下,用info gdt命令查看gdt表,可以看到TSS正确加载到第四个描述符中。
进程实现
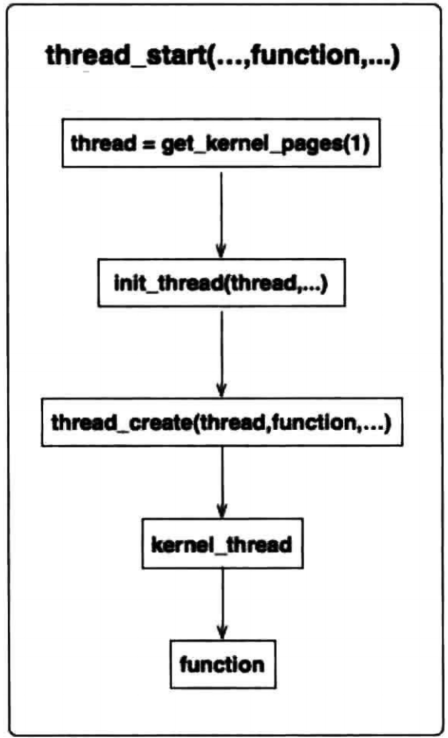
实现进程的过程是在之前的线程基础上进行的,在创建线程的时候是将栈的返回地址指向了kernel_thread函数,通过该函数调用线程函数实现的,其执行流程如下,我们只需要把执行线程的函数换成创建进程的函数就可以了
与线程不同的是,每个进程都单独有4GB虚拟地址空间,所以,需要单独为每个进程维护一个虚拟地址池,用来标记该进程中地址分配信息
1 | /* 进程或线程的pcb,程序控制块 */ |
用户进程创建页表的实现在memory.c中添加
1 | // 在虚拟内存池中申请pg_cnt个虚拟页 |
我们还需让用户进程工作在3环下,这就需要我们从高特权级跳到低特权级。一般情况下,CPU不允许从高特权级转向低特权级,只有从中断返回或者从调用门返回的情况下才可以。这里我们采用从中断返回的方式进入3特权级,需要制造从中断返回的条件,构造好栈的内容之后执行iretd指令,下面是添加的函数
1 | //构建用户进程初始上下文信息 |
激活页表,其参数可能是进程也可能是线程
1 | /* 激活页表 */ |
创建用户进程的页目录表
1 | uint32_t *create_page_dir(void) |
创建用户进程filename并将其添加到就绪队列中
1 | /* 创建用户进程 */ |
要执行用户进程,我们需要通过调度器将其调度,不过这里因为用户进程是ring3,内核线程是ring0,故我们需要修改调度器
1 | /* 实现任务调度 */ |
最后在main中添加测试代码,用内核线程帮进程打印数据
1 | [...] |
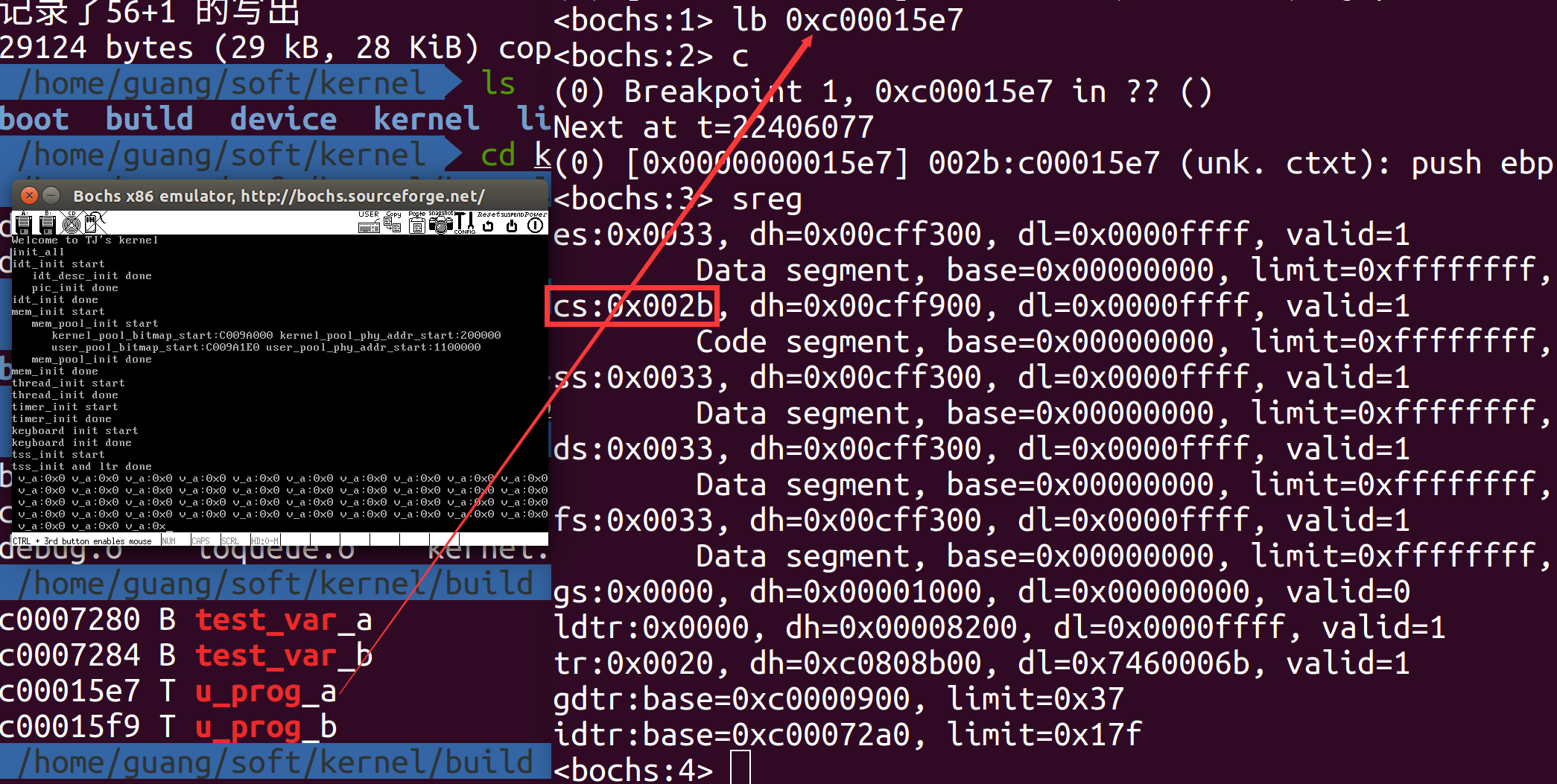
测试结果如下所示,在u_prog_a进程下断点观察cs为0x002b,和预期相符
完善内核
系统调用
实现getpid
系统调用就是让用户进程调用了操作系统的功能,我们需要实现两部分,一部分属于用户空间,提供接口函数,另一部分作为内核具体实现。Linux中直接的系统调用是宏_syscall,不过现在已经废弃并被库函数syscall替代,为了内核实现更简单,我们参考_syscall来实现系统调用,其用法可以用man命令自行查询,实现思路大致如下:
- 调用中断门实现系统调用,效仿Linux用0x80作为系统调用入口
- 在IDT中安装0x80号中断对应的描述符,在该描述符中注册系统调用对应的中断处理例程
- 建立系统调用子功能表,利用eax寄存器中的子功能号在该表中索引相应的处理函数
- 用宏实现用户空间系统调用接口_syscall,最大只支持3个参数,eax为功能号,ebx保存第一个参数,ecx保存第二个参数,edx保存第三个参数
我们就按照这个步骤一步步完成代码,首先实现获取任务自己的PID
增加0x80号中断描述符
1 |
|
在lib/user/目录下新添加syscall文件,实现调用接口
1 | /* 无参数的系统调用 */ |
增加0x80的处理例程
1 | [bits 32] |
初始化系统调用和实现sys_getpid,由userprog目录下新创建的syscall-init实现
1 |
|
线程初始化函数中分配pid值
1 | struct lock pid_lock; // 分配pid锁 |
syscall文件中继续添加系统调用
1 | /* 返回当前任务pid */ |
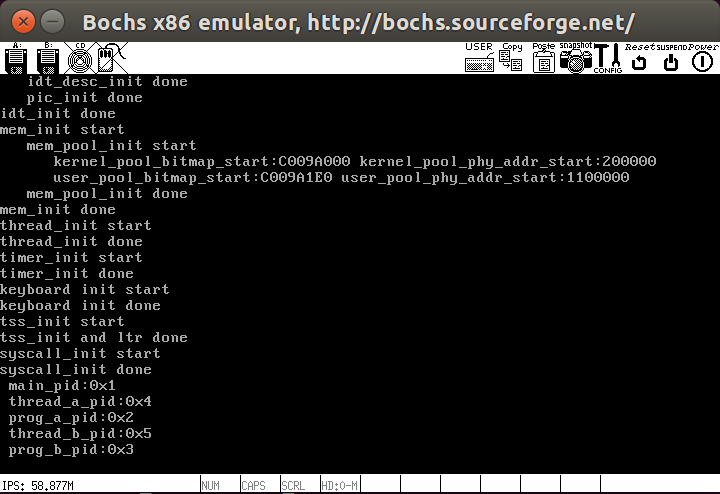
最后在main函数中测试一下效果,其中用户接口函数为getpid(),内核实现为sys-getpid(),分别由用户进程和内核线程调用
1 | int prog_a_pid = 0, prog_b_pid = 0; |
测试结果如下
实现write和printf
因为我们还没有实现文件系统,故不能模仿Linux中write的系统调用,不过我们可以略去第一个参数,实现一个简单版的write,首先根据前面获取pid的基础,我们先实现提供用户调用接口,添加功能号,初始化等工作
1 | uint32_t write(char *str) |
添加处理程序
1 | uint32_t sys_write(char *str) |
printf原理是由write和vsprint组合,首先需要知道可变参数的原理,一般平时使用的函数,参数的个数都是已知的。函数占用的是静态内存,也就是说再编译期就要确定为其分配多大的空间。而对于可变参数则不一样,比如
1 | int printf(const char *format, ...); |
不过调用printf的时候我们指定了format,根据format的内容其实也就确定了参数内容,比如一个%d就多一个参数。这样我们就可以通过遍历format中的字符,筛选出%号后的数据进行单独处理即可
1 | /* 将参数ap按照格式format输出到字符串str,并返回替换后str长度 */ |
最后就是printf的实现
1 |
|
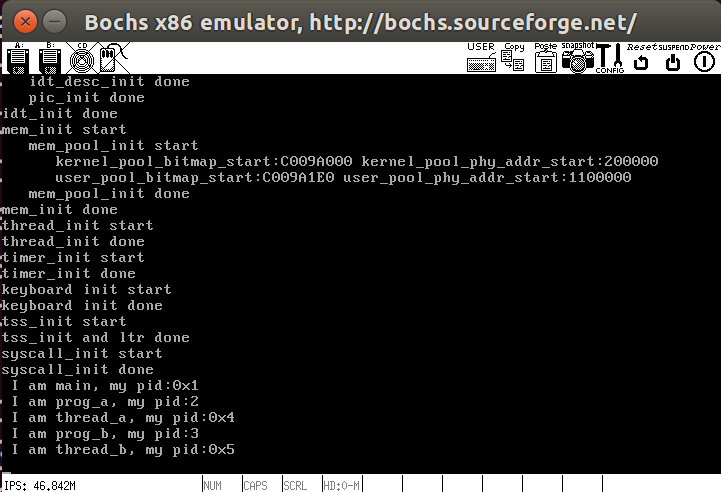
我们在main中重新测试一下效果
1 | int main(void) { |
测试结果如下
完善堆内存
接下来我们需要重新实现malloc和free函数,虽然之前的内容中已经实现过内存分配的功能,但之前的内存管理模块中只是实现了内核空间的内存分配,而且每次分配的空间都是以页为单位,也就是只能分配页的整数倍的空间,我们需要优化使其能分配用户想要申请的大小。
malloc
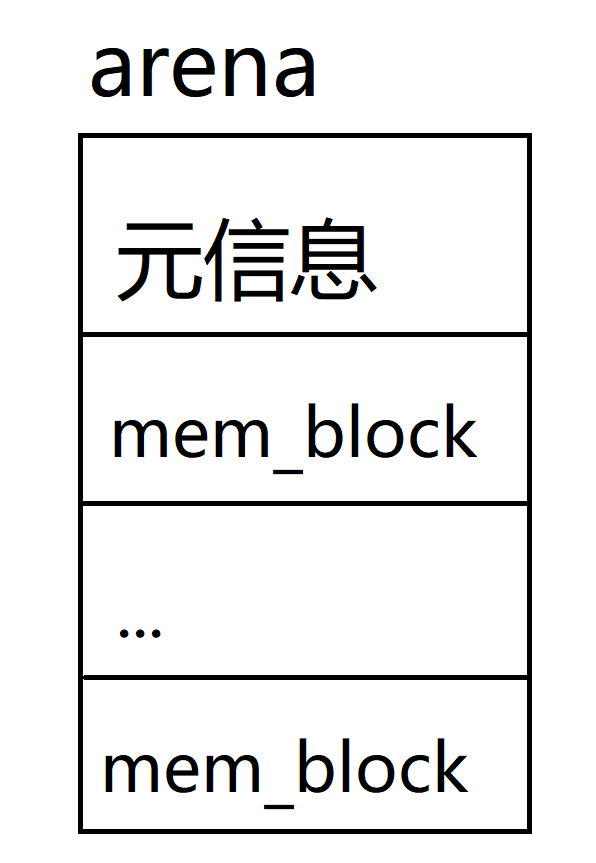
首先引入arena的概念,arena是一大块的内存被划分的多个小的内存块的内存仓库。按照内存块的大小,可以划分成不同规格的arena。比如一种arena中全是32byte的内存块,它就只相应32byte以下内存空间的分配。这一整块arena的大小同样是页的整数倍,按照申请内存空间的大小,这个arena可能是1页或者多页。其结构由两部分组成,一是这块内存的元信息,用来描述这个arena中剩余的内存块,二是内存池区域,里面就是多个大小相同的内存块。
当一块arena大小的内存分配完的时候,也就是该arena中的所有mem_block都分配出去了,就需要新增一个与之前arena规格相同的arena来满足内存的需求,那么这些相同规格arena之前同样需要一个结构来进行管理,这个结构用来记录arena的规格以及同规格arena中所有空闲内存块链表,也称为内存块描述符。

当申请的内存大于1024byte时,arena中的元信息就为NULL,剩下的所有空间合为一个mem_block,也就是说只有一个为NULL的元信息和一块大内存。我们将arena划分为7种规格大小,分别为16byte, 32byte, 64byte, …. 1024byte。一个arena一般占用1页也就是4096byte,假设arena中的元信息在设计中它会占用12byte大小,对于规格为16byte的arena来说,它有(4096 - 12) / 16 = 255个内存块,有4byte的空间被浪费。
下面进行具体实现,修改memory.h文件
1 | /* 内存块 */ |
初始化在.c文件中
1 | /* 内存仓库arena元信息 */ |
下面实现sys_malloc,该函数就是在堆上分配指定大小的空间。这也是malloc的底层实现
1 | // 堆中申请size字节 |
free
释放内存和分配内存过程相反,首先看一下申请的过程:
- 在虚拟地址池中分配虚拟地址
- 在物理内存池中分配物理地址
- 在页表中完成虚拟地址到物理地址的映射
与之相反的释放的过程如下:
- 在物理地址池中释放物理地址
- 在页表中去除虚拟地址的映射,原理是将pte中的P位置0
- 在虚拟地址池中释放虚拟地址
具体实现也在memory文件中
1 | /* 将物理地址pg_phy_addr回收到物理内存池 */ |
释放虚拟地址中物理页框的步骤是,先调用pfree清空物理页地址,在调用page_table_pte_remove删除页表中此地址的pte,最后调用vaddr_remove清除虚拟地址位图中的相应位
1 | /* 释放以虚拟地址vaddr为起始的cnt个物理页框 */ |
下面实现sys_free,对释放的内存是否大于1024有不同的处理,大于则将页框在虚拟内存池和物理内存池的位图中将相应位置置0,小于则将arena中的内存块重新放回到内存块描述符中的空闲块链表free_list
1 | /* 回收内存ptr */ |
最后我们在syscall文件中添加我们的系统调用
1 | /* 申请size字节大小的内存,并返回结果 */ |
更新系统调用号数组表
1 | /* 初始化系统调用 */ |
最后进行测试,下面是main中主要测试代码,申请内存大小对应规格均为256,所以会出现累加的情况
1 | int main(void) { |
测试结果如下,地址确实是连续的,和预期相符