0x00:Introduction
本片文章主要逆向一些CTF中的常见算法,对算法的原理和实现结合进行分析,总结一些常用的方法以供参考
0x01:Base series
0x01:Base64
介绍
Base64可以将ASCII字符串或者是二进制编码成只包含A—Z,a—z,0—9,+,/ 这64个字符( 26个大写字母,26个小写字母,10个数字,1个+,一个 / 刚好64个字符)。这64个字符用6个bit位就可以全部表示出来,一个字节有8个bit 位,那么还剩下两个bit位,这两个bit位用0来补充。其实,一个Base64字符仍然是8个bit位,但是有效部分只有右边的6个 bit,左边两个永远是0。Base64的编码规则是将3个8位字节(3×8=24位)编码成4个6位的字节(4×6=24位),之后在每个6位字节前面,补充两个0,形成4个8位字节的形式,那么取值范围就变成了0~63。又因为2的6次方等于64,所以每6个位组成一个单元。一般在CTF逆向题目中base64的加密过程主要是用自定义的索引表,所以如果能一眼能看出是base64加密就会节约很多时间。
加密过程
- base64的编码都是按字符串长度,以每3个8bit的字符为一组,
- 然后针对每组,首先获取每个字符的ASCII编码,
- 然后将ASCII编码转换成8bit的二进制,得到一组3*8=24bit的字节
- 然后再将这24bit划分为4个6bit的字节,并在每个6bit的字节前面都填两个高位0,得到4个8bit的字节
- 然后将这4个8bit的字节转换成10进制,对照Base64编码表 ,得到对应编码后的字符。
索引表如下
| 索引 | 对应字符 | 索引 | 对应字符 | 索引 | 对应字符 | 索引 | 对应字符 |
|---|---|---|---|---|---|---|---|
| 0 | A | 17 | R | 34 | i | 51 | z |
| 1 | B | 18 | S | 35 | j | 52 | 0 |
| 2 | C | 19 | T | 36 | k | 53 | 1 |
| 3 | D | 20 | U | 37 | l | 54 | 2 |
| 4 | E | 21 | V | 38 | m | 55 | 3 |
| 5 | F | 22 | W | 39 | n | 56 | 4 |
| 6 | G | 23 | X | 40 | o | 57 | 5 |
| 7 | H | 24 | Y | 41 | p | 58 | 6 |
| 8 | I | 25 | Z | 42 | q | 59 | 7 |
| 9 | J | 26 | a | 43 | r | 60 | 8 |
| 10 | K | 27 | b | 44 | s | 61 | 9 |
| 11 | L | 28 | c | 45 | t | 62 | + |
| 12 | M | 29 | d | 46 | u | 63 | / |
| 13 | N | 30 | e | 47 | v | ||
| 14 | O | 31 | f | 48 | w | ||
| 15 | P | 32 | g | 49 | x | ||
| 16 | Q | 33 | h | 50 | y |
例子
第一个例子以base64加密SLF为例子,过程如下
1 | 字符串 S L F |
第二个例子以base64加密M为例子,过程如下
1 | 字符串 M |
实现
最上面的base64char索引表可以自定义,这里用c实现
1 |
|
输入如下
1 | C:\Users\thunder>"D:\AlgorithmTest.exe" |
上面的代码是base64加密和解密字符串a45rbcd我们用IDA查看,base64char即是我们的索引表
1 | int __cdecl base64_encode(const char *sourcedata, char *base64) |
辨别
其实辨别很简单,有很多的方法,最简单的方法就是动态调试,直接用OD或者IDA动态调试,多输入几组数据,观察加密后的字符串,存在=这种字符串多半都有base64加密。 如果不能动态调试那就用IDA静态观察,观察索引表,观察对输入的操作,比如上面很明显的三次右移操作。
解密
一般解密用python来实现
1 | import base64 |
在线解密网站 : https://www.qqxiuzi.cn/bianma/base.php
CTF参考例题
DDCTF2019 Reverse2
0x02:Base32
原理
Base32编码是使用32个可打印字符(字母A-Z和数字2-7)对任意字节数据进行编码的方案,编码后的字符串不用区分大小写并排除了容易混淆的字符,可以方便地由人类使用并由计算机处理。
| 值 | 符号 | 值 | 符号 | 值 | 符号 | 值 | 符号 | |||
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | A | 8 | I | 16 | Q | 24 | Y | |||
| 1 | B | 9 | J | 17 | R | 25 | Z | |||
| 2 | C | 10 | K | 18 | S | 26 | 2 | |||
| 3 | D | 11 | L | 19 | T | 27 | 3 | |||
| 4 | E | 12 | M | 20 | U | 28 | 4 | |||
| 5 | F | 13 | N | 21 | V | 29 | 5 | |||
| 6 | G | 14 | O | 22 | W | 30 | 6 | |||
| 7 | H | 15 | P | 23 | X | 31 | 7 | |||
| 填充 | = |
Base32将任意字符串按照字节进行切分,并将每个字节对应的二进制值(不足8比特高位补0)串联起来,按照5比特一组进行切分,并将每组二进制值转换成十进制来对应32个可打印字符中的一个。
由于数据的二进制传输是按照8比特一组进行(即一个字节),因此Base32按5比特切分的二进制数据必须是40比特的倍数(5和8的最小公倍数)。例如输入单字节字符“%”,它对应的二进制值是“100101”,前面补两个0变成“00100101”(二进制值不足8比特的都要在高位加0直到8比特),从左侧开始按照5比特切分成两组:“00100”和“101”,后一组不足5比特,则在末尾填充0直到5比特,变成“00100”和“10100”,这两组二进制数分别转换成十进制数,通过上述表格即可找到其对应的可打印字符“E”和“U”,但是这里只用到两组共10比特,还差30比特达到40比特,按照5比特一组还需6组,则在末尾填充6个“=”。填充“=”符号的作用是方便一些程序的标准化运行,大多数情况下不添加也无关紧要,而且,在URL中使用时必须去掉“=”符号。
与Base64相比,Base32具有许多优点:
- 适合不区分大小写的文件系统,更利于人类口语交流或记忆。
- 结果可以用作文件名,因为它不包含路径分隔符 “/”等符号。
- 排除了视觉上容易混淆的字符,因此可以准确的人工录入。(例如,RFC4648符号集忽略了数字“1”、“8”和“0”,因为它们可能与字母“I”,“B”和“O”混淆)。
- 排除填充符号“=”的结果可以包含在URL中,而不编码任何字符。
Base32也比Base16有优势:
- Base32比Base16占用的空间更小。(1000比特数据Base32需要200个字符,而Base16则为250个字符)
Base32的缺点:
- Base32比Base64多占用大约20%的空间。因为Base32使用8个ASCII字符去编码原数据中的5个字节数据,而Base64是使用4个ASCII字符去编码原数据中的3个字节数据。
解密
1 | import base64 |
在线网站 : https://www.qqxiuzi.cn/bianma/base.php
CTF参考例题
2017第二届广东省强网杯线上赛 Nonstandard
0x03:Base16
原理
Base16编码使用16个ASCII可打印字符(数字0-9和字母A-F)对任意字节数据进行编码。Base16先获取输入字符串每个字节的二进制值(不足8比特在高位补0),然后将其串联进来,再按照4比特一组进行切分,将每组二进制数分别转换成十进制,在下述表格中找到对应的编码串接起来就是Base16编码。可以看到8比特数据按照4比特切分刚好是两组,所以Base16不可能用到填充符号“=”。
Base16编码后的数据量是原数据的两倍:1000比特数据需要250个字符(即 250*8=2000 比特)。换句话说:Base16使用两个ASCII字符去编码原数据中的一个字节数据。
| 值 | 编码 | 值 | 编码 |
|---|---|---|---|
| 0 | 0 | 8 | 8 |
| 1 | 1 | 9 | 9 |
| 2 | 2 | 10 | A |
| 3 | 3 | 11 | B |
| 4 | 4 | 12 | C |
| 5 | 5 | 13 | D |
| 6 | 6 | 14 | E |
| 7 | 7 | 15 | F |
Base16编码是一个标准的十六进制字符串(注意是字符串而不是数值),更易被人类和计算机使用,因为它并不包含任何控制字符,以及Base64和Base32中的“=”符号。输入的非ASCII字符,使用UTF-8字符集。
解密
1 | import base64 |
在线网站 : https://www.qqxiuzi.cn/bianma/base.php
0x02:RC4
原理
在密码学中,RC4(来自Rivest Cipher 4的缩写)是一种流加密算法,密钥长度可变。它加解密使用相同的密钥,因此也属于对称加密算法。RC4是有线等效加密(WEP)中采用的加密算法,也曾经是TLS可采用的算法之一。
加密过程
| 参数 | 作用 |
|---|---|
| S-box(S) | 256长度的char型数组,定义为: unsigned char sBox[256] |
| Key(K) | 自定义的密钥,用来打乱 S-box |
| pData | 用来加密的数据 |
初始化 S (256字节的char型数组),key 是我们自定义的密钥,用来打乱 S ,i 确保 S-box 的每个元素都得到处理, j 保证 S-box 的搅乱是随机的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19/*初始化函数*/
void rc4_init(unsigned char*s, unsigned char*key, unsigned long Len)
{
int i = 0, j = 0;
char k[256] = { 0 };
unsigned char tmp = 0;
for (i = 0; i < 256; i++)
{
s[i] = i; // 赋值 S
k[i] = key[i%Len]; // 赋值 K
}
for (i = 0; i < 256; i++)
{
j = (j + s[i] + k[i]) % 256; // 开始混淆
tmp = s[i];
s[i] = s[j]; // 交换s[i]和s[j]
s[j] = tmp;
}
}加密过程将 S-box 和明文进行 xor 运算,得到密文,解密过程也完全相同
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17/*加解密*/
void rc4_crypt(unsigned char*s, unsigned char*Data, unsigned long Len)
{
int i = 0, j = 0, t = 0;
unsigned long k = 0;
unsigned char tmp;
for (k = 0; k < Len; k++)
{
i = (i + 1) % 256;
j = (j + s[i]) % 256;
tmp = s[i];
s[i] = s[j]; // 交换s[x]和s[y]
s[j] = tmp;
t = (s[i] + s[j]) % 256;
Data[k] ^= s[t];
}
}
实现
下面是 C 实现的代码
1 |
|
运行结果如下
1 | C:\Users\thunder>"D:\AlgorithmTest.exe" |
上面的代码是rc4加密字符串这是一个用来加密的数据Data,key = justfortest,我们放入IDA观察,初始化函数如下
1 | void __cdecl rc4_init(char *s, char *key, unsigned int Len) |
加密函数如下
1 | void __cdecl rc4_crypt(char *s, char *Data, unsigned int Len) |
辨别
从IDA中可以看到有很多的 %256 操作,因为 s 盒的长度为256,所以这里很好判断,如果在CTF逆向过程中看到有多次 %256 的操作最后又有异或的话那可以考虑是否是RC4密码
解密
python实现如下
1 | # -*- coding: utf-8 -*- |
输出如下
1 | [Running] python -u "/home/thunder/Desktop/CTF/crypt/example/rc4_example/test.py" |
在线解密网站:https://www.sojson.com/encrypt_rc4.html
0x03:SM4
介绍
SM4.0(原名SMS4.0)是中华人民共和国政府采用的一种分组密码标准,由国家密码管理局于2012年3月21日发布。相关标准为“GM/T 0002-2012《SM4分组密码算法》(原SMS4分组密码算法)”。在商用密码体系中,SM4主要用于数据加密,其算法公开,分组长度与密钥长度均为128bit,加密算法与密钥扩展算法都采用32轮非线性迭代结构,S盒为固定的8比特输入8比特输出。SM4.0中的指令长度被提升到大于64K(即64×1024)的水平,这是SM 3.0规格(渲染指令长度允许大于512)的128倍。
加密过程
这里我简要介绍一下SM4算法,详细的过程可以查看参考链接,首先我们要知道SM4是一个对称加密算法,也就是说加密和解密的密钥相同,首先我们要清楚下面几个概念
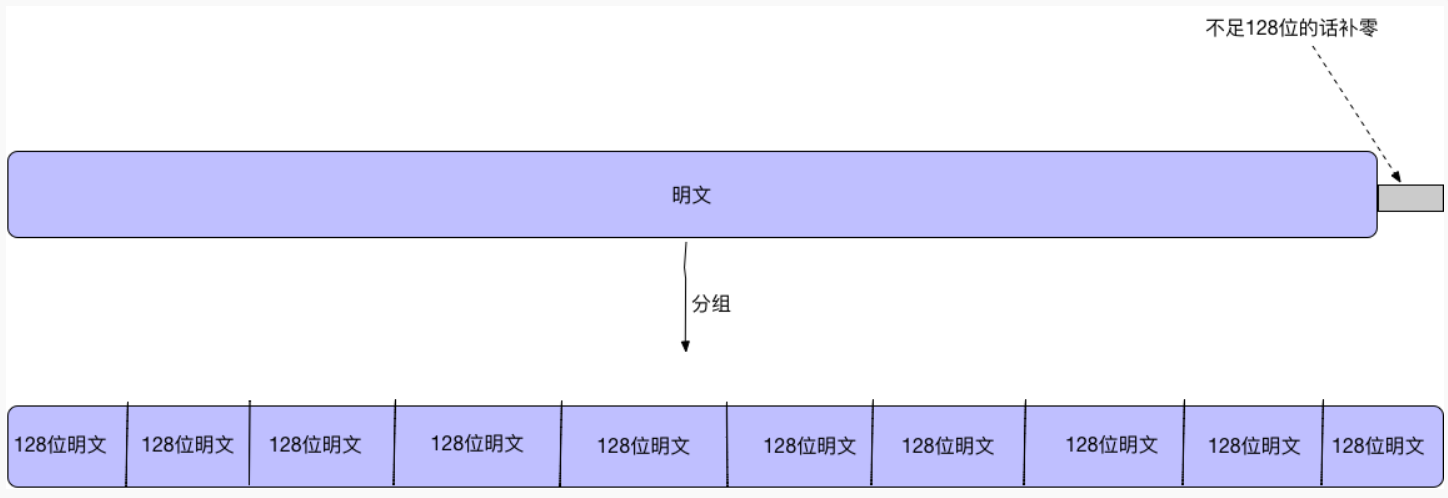
SM4是分组密码,所以我们要将明文分组,将明文分成128位一组
S(Sbox)盒负责置换我们的明文
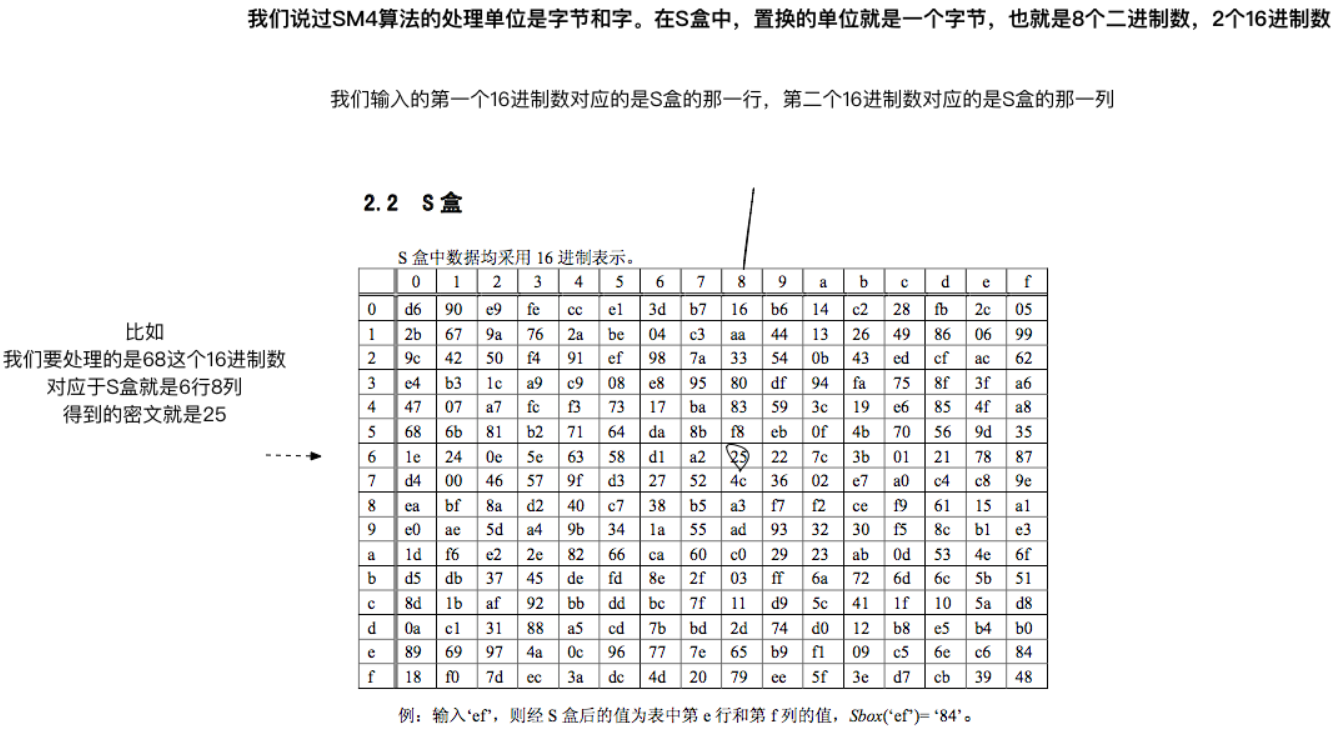
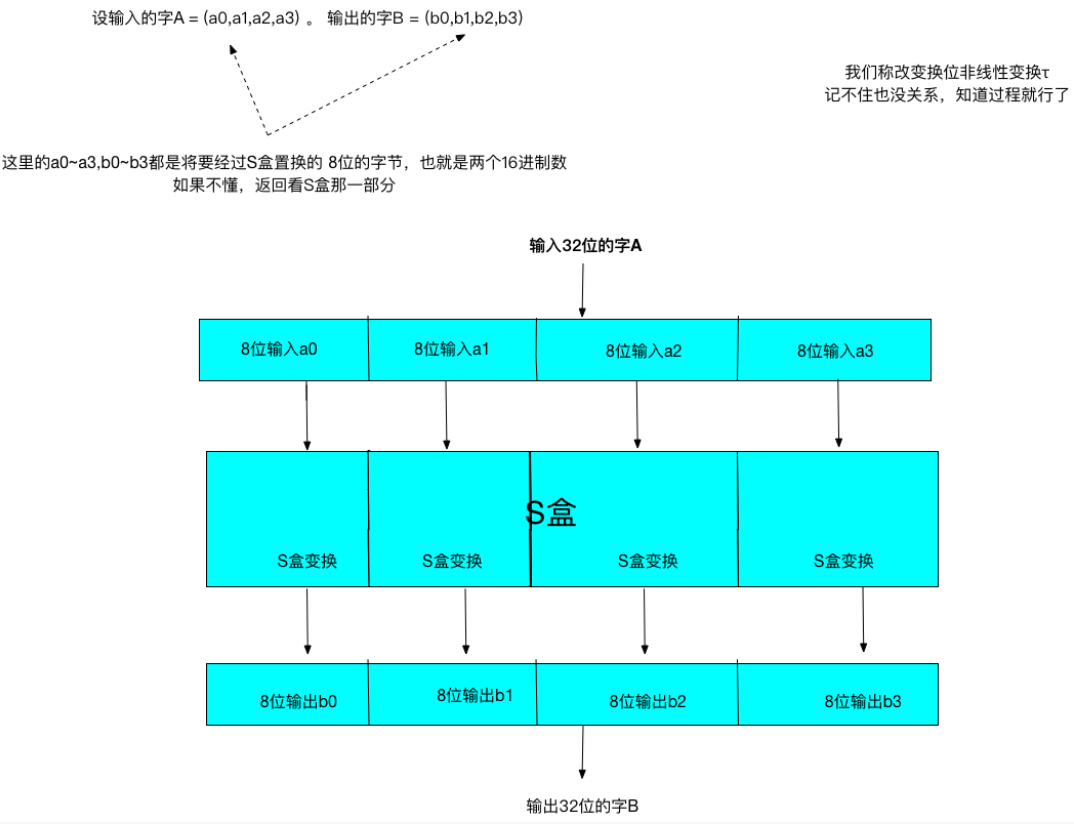
因为SM4面向的是32bit的字(word),S盒处理的是两个16进制数也就是8bit的字节,所以我们要用4个S盒来置换
轮函数F的概念如下图,以字为单位进行加密运算,称一次迭代运算为一轮变换

合成置换T就是非线性变换和线性变换的一个组合过程

了解上述一些概念之后加密解密的过程如下图

在SM4算法中,轮秘钥的产生是通过用户选择主秘钥作为基本的秘钥数据,在通过一些算法生成轮秘钥,在密钥拓展中,我们通过一些常数对用户选择的主钥进行操作,增大随机性。密钥扩展算法如下

实现
代码出自这里
sm4.c加密解密函数的实现
1 | // sm4.c |
sm4.h头文件,mode选择加密模式
1 | /** |
测试代码
1 | // test.c |
运行结果
1 | C:\Users\thunder>"D:\AlgorithmTest.exe" |
解密
pysm4是国密SM4算法的Python实现,这里下载
1 | from pysm4 import encrypt, decrypt |
辨别
CTF逆向可以通过判断S盒的值来猜测SM4算法,通过S盒生成4个8位的字符,我们将上面实现代码放入IDA中查看,我们可以通过输入明文密钥的格式来猜测SM4算法
1 | __int64 main() |
算法中的T变换观察返回值也有很明显的特征
1 | unsigned int __cdecl sm4F(unsigned int x0, unsigned int x1, unsigned int x2, unsigned int x3, unsigned int rk) |
例题
2019ciscn-bbvvmm
下面的代码和上面的对比可以很容易的猜到SM4
1 | unsigned __int64 __fastcall sub_400EE2(__int64 a1, __int64 a2, __int64 a3, __int64 a4, __int64 a5) |
0x04:Reference
Base
1 | http://www.cnblogs.com/hongru/archive/2012/01/14/2321397.html |
RC4
1 | https://blog.csdn.net/Fly_hps/article/details/79918495 |
SM4
1 | https://neuqzxy.github.io/2017/06/15/%E6%AC%A3%E4%BB%94%E5%B8%A6%E4%BD%A0%E9%9B%B6%E5%9F%BA%E7%A1%80%E5%85%A5%E9%97%A8SM4%E5%8A%A0%E5%AF%86%E7%AE%97%E6%B3%95/ |