完善内核
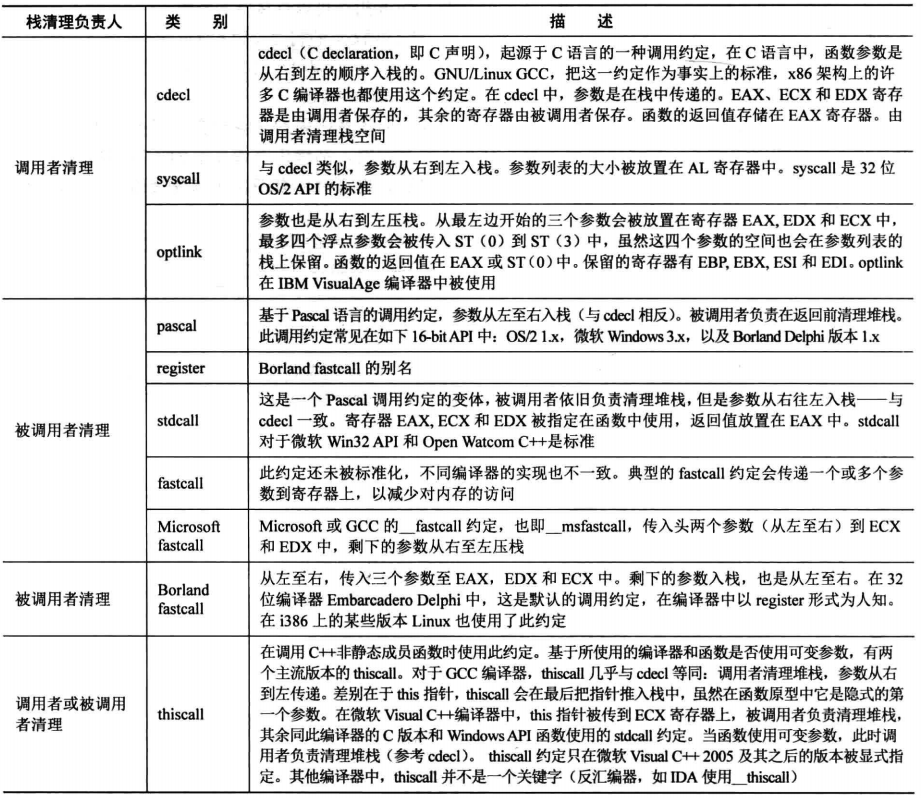
调用约定
调用约定主要体现在以下三方面:
- 参数的传递方式,参数是存放在寄存器中还是栈中
- 参数的传递顺序,是从左到右传递还是从右到左传递
- 是调用者保存寄存器环境还是被调用者保存
有如下常见的调用约定,我们主要关注cdecl、stdcall、thiscall即可
cdecl是默认c的调用约定,调用者将所有参数从右向左入栈,被调用者清理参数所占栈空间,举个例子
1 | int subtract(int a, int b); // 被调用者 |
调用者汇编如下
1 | push 2 |
被调用者汇编如下
1 | push ebp ; 备份ebp |
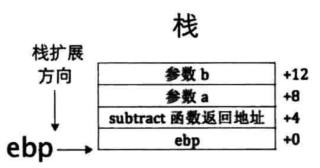
进入subtract函数时栈中的布局如下
stdcall是微软Win32 API的标准,调用者将所有参数从右向左入栈,并且调用者清理参数所占栈空间,还是上面的例子,调用者汇编如下
1 | push 2 |
被调用者汇编如下
1 | push ebp ; 备份ebp |
thiscall则在C++中非静态成员函数的默认调用约定,其主要区别是ecx会多保存一个this指针指向操作的对象。
系统调用
为了更加理解系统调用,在后面会更频繁的结合C和汇编进行操作,下面做一个实验,分别用三种方式调用write函数,模拟下面C调用库函数的过程
1 |
|
模拟代码syscall_write.S如下
1 | section .data |
运行结果如下

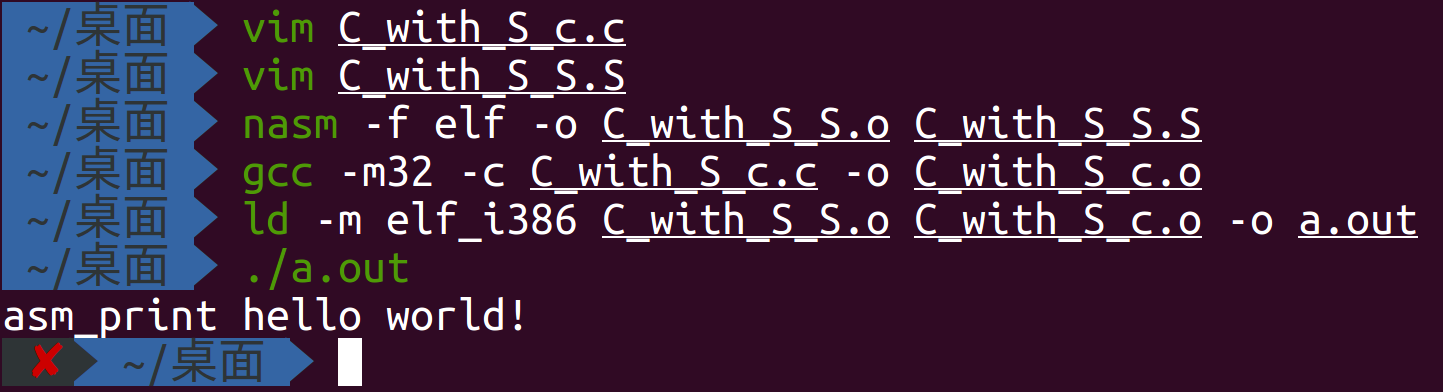
既然我们用汇编模拟了C中的write函数,下面就用C结合汇编进行第二个实验
C_with_S_c.c
1 | extern void asm_print(char*,int); |
C_with_S_S.S
1 | section .data |
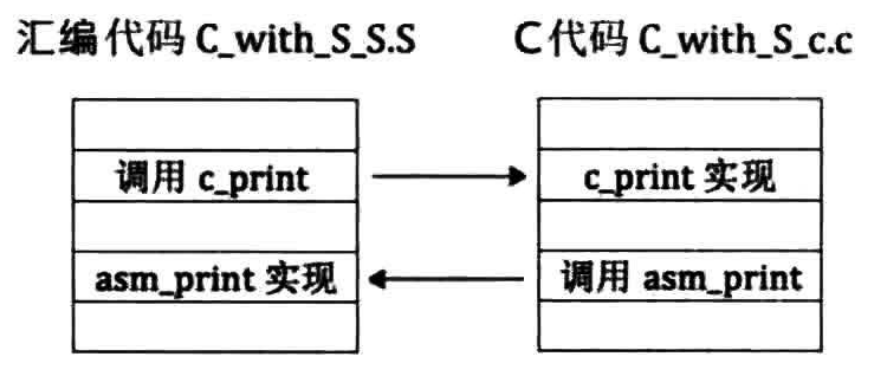
其调用关系如下图
编译过程如下所示
实现打印函数
对于字符的打印主要是对显卡端口的操作,所以是用汇编实现,这里新键一个lib目录,里面添加一个头文件,主要申请一些数据结构信息,来自Linux源码
1 |
|
再新建一个user目录和一个kernel目录,我们的print实现代码就在kernel目录下的print.S,这个函数比较复杂,处理流程如下
- 备份寄存器现场
- 获取光标坐标值,光标坐标值是下一个可打印字符的位置
- 获取待打印的字符
- 判断字符是否为控制字符,如回车、换行、退格符需要特殊处理
- 判断是否需要滚屏
- 更新光标坐标值,使其指向下一个打印字符的位置
- 恢复寄存器现场,退出
首先需要知道光标和字符的区别,它们之间没有任何关系,光标位置保存在光标寄存器中,可以手动维护,这就需要参考书中的显卡寄存器索引(P264),我们需要操作CRT控制数据寄存器中索引为0x0E的Cursor Location High Register和索引为0x0F的Cursor Location Low Register分别用来储存光标坐标的高8位和低8位。访问CRT寄存器,需要首先往端口地址为0x3D4寄存器写入索引,然后再从端口0x3D5的数据寄存器读写数据,另外一些特殊字符需要特殊处理,其中还会涉及到滚屏的处理,我们的屏幕是80*25大小的,步骤如下:
- 将第1~24行搬到0~23行,覆盖第0行
- 将24行也就是最后一行用空格覆盖,看起来像新的一行
- 光标移动到第24行行首
1 | TI_GDT equ 0 |
头文件print.h
1 |
|
下面测试代码main.o
1 |
|
目前为止的目录结果如下
1 | . |
编译需要用到的几条命令,目录不同会有变化
1 | sudo nasm -f elf -o print.o print.S |
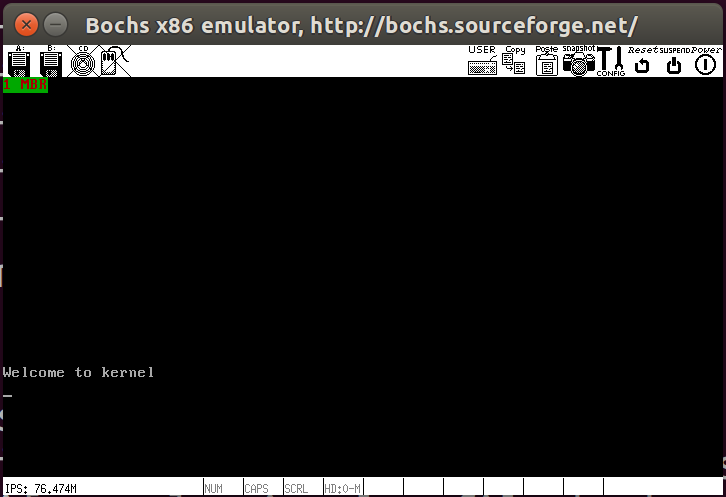
显示结果如下
下面把put_char函数封装起来,put_str通过put_char来打印以0字符结尾的字符串,思想就是循环打印直到0结束
1 | ; -------------------------------------------- |
print.h中增加一行申明
1 |
|
main.c对其进行调用测试
1 |
|
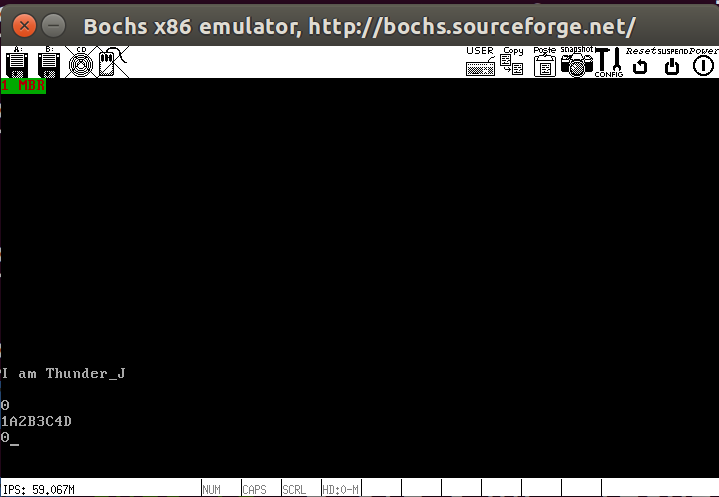
测试结果如下
前面是实现对字符的打印,下面需要增加对整数的打印,逐位处理,A~F再单独处理,再增加对高位多余0的处理,详情见注释
1 | ;-------------------- 将小端字节序的数字变成对应的ascii后,倒置 ----------------------- |
在print.h增加一行put_int的申明注释,main.c中增加测试代码即可,测试结果如下所示
中断
中断的存在极大提高了计算机的效率,可分为外部中断和内部中断。
外部中断的中断源为某个硬件,CPU为中断信号提供了两条信号线分别是INTR和NMI,如下图所示,从INTR引脚收到的中断都是不影响系统运行的,可以随时处理,不会影响到CPU的执行。也称为可屏蔽中断。可以通过eflag中的IF位将所有这些外部中断屏蔽
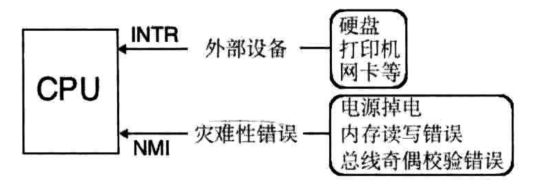
内部中断可分为软中断和异常
软中断
顾名思义是软件主动发起的中断,不受eflags中的IF位的影响,有如下指令:
- “int 8位立即数”,通过它进行系统调用
- int3,int和3之间无空格,用于调试
- into,中断溢出指令,当OF位也为1时,触发4号中断
- bound,检查数组索引越界指令,越界时触发5号中断
- ud2,未定义指令,触发6号中断
异常
异常是指令执行期间CPU内部产生的错误引起的,也不受eflags中的IF位的影响,按照轻重程度分为三种
- Fault,也称故障。属于可被修复的一种类型,当发生此类异常时,CPU将机器状态恢复到异常之前的状态 ,之后调用中断处理程序,通常都能够被解决。缺页异常就属于此种异常
- Trap,也称陷阱。此异常通常在调试中。
- Abort,也称终止。程序发生了此类异常通常就无法继续执行下去,操作系统会将此程序从进程表中去除。
中断描述符表
中断描述符表是保护模式下用于存储中断处理程序入口的表,当CPU接受到一个中断时,需要根据该中断的中断向量号在此表中检索对应的描述符,在该描述符中找到中断处理程序的起始地址,然后执行中断处理程序,这和之前段描述符非常类似,类比学习即可。
实模式下用于中断处理程序入口的表叫做中断向量表(IVT),保护模式下则是中断描述符表(IDT)。
IVT在实模式下位于0~0x3ff共1024个字节,又知IVT可容纳256个中断向量,故每个中断向量用4字节描述;对比IVT,IDT表地址不受限制,在哪里都可以,每个描述符用8字节描述。这里主要讨论IDT,在IDT中描述符称之为门,也就是之前介绍过的门,这里再区别一下门和段描述符
- 段描述符中描述的是一片内存区域
- 门描述符描述的是一段代码,除调用门外,任务门、中断门、陷阱门都可以存在于中断描述符中
IDT位置不固定,故CPU找到它需要通过一个寄存器IDTR,如下图,其中0~15位是表界限,也就是IDT大小减一,第16~47位是IDT的基地址,和之前的GDTR是一个原理

16位的表界限范围是0~0xffff,即64KB,可容纳的描述符个数是64KB/8=8K=8192个。特别注意的是GDT中的第0个段描述符是不可用的,但IDT却无此限制,第0个门描述符也是可用的,处理器只支持256个中断,即0~254,中断描述符中其他的描述符不可用,还需要注意的是门描述符中的P位,构建IDT时需要将其置为0,表示门描述符的中断处理程序不在内存中。加载IDTR需要用到lidt指令,用法是lidt 48位内存数据
中断的处理过程总结如下
- 处理器根据中断向量号定位中断门描述符
- 处理器进行特权级检查
- 执行中断处理程序
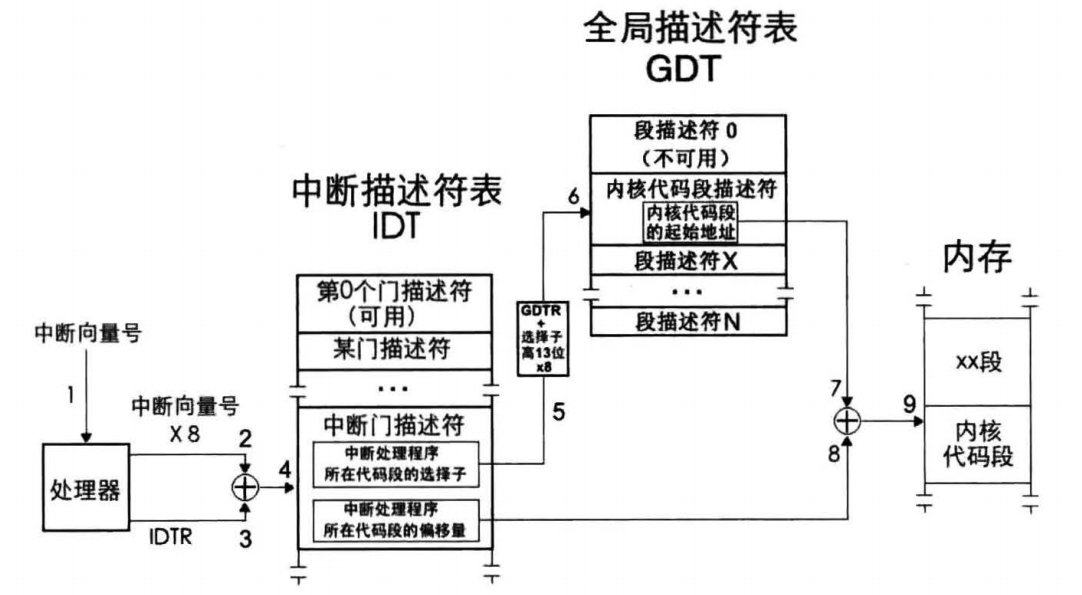
中断发生之后需要执行中断处理程序,该中断处理程序是通过中断门描述符中保存的代码段选择子和段内偏移找到的,这个时候就需要重新加载段寄存器,也就是说需要在栈中保存一些寄存器信息(CS:EIP、eflags等),保证中断之后执行的流程正确,当特权级变化的时候,压栈如下图所示
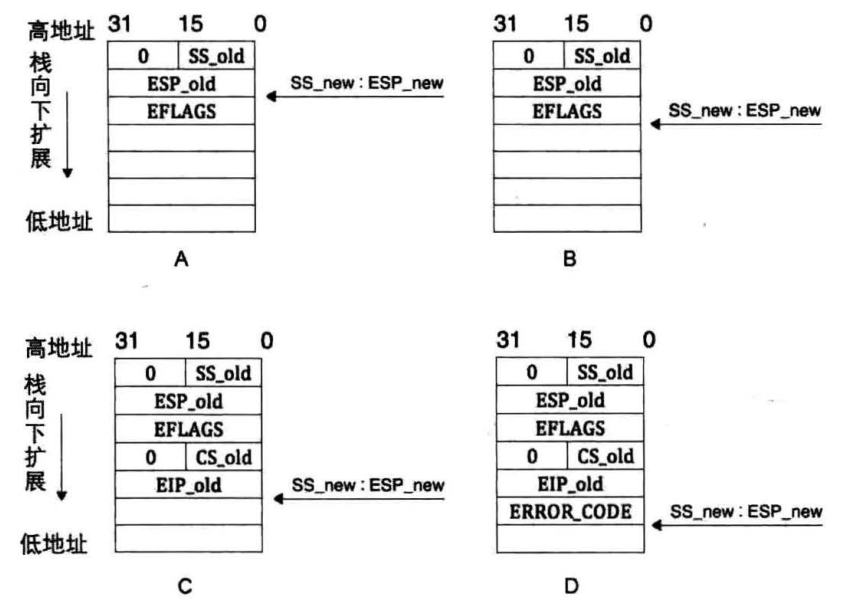
图A、B:在发生中断是通过特权级的检测,发现需要向高特权级转移,所以要保存当前程序栈的SS和ESP的值,在这里记为ss_old, esp_old,然后在新栈中压入当前程序的eflags寄存器。
图C、D:由于要切换目标代码段,这种段间转移,要对CS和EIP进行备份,同样将其存入新栈中。某些异常会有错误码,用来标识异常发生在哪个段上,对于有错误码的情况,要将错误码也压入栈中。
当特权级没有变化的时候,就不需要压入旧栈的SS和EIP
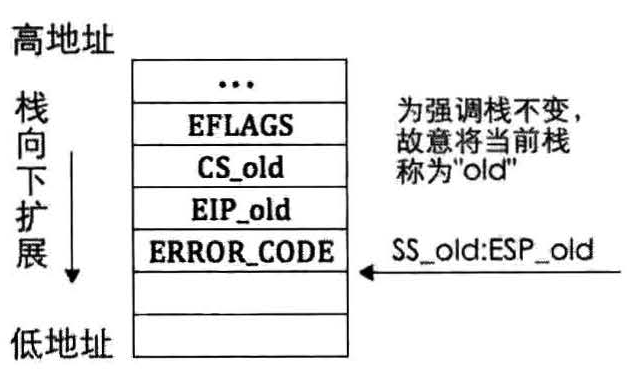
返回的时候通过指令 iret 完成,iret 指令会从栈顶依次弹出EIP、CS、EFLAGS,根据特权级的变化还有ESP、SS。但是该指令并不验证数据的正确性,而且他从栈中弹出数据的顺序是不变的,也就是说,在有error_code的情况下,iret返回时并不会主动跳过这个数据,需要我们手动进行处理。
编写中断处理程序
下面通过操作8259A芯片实现第一个中断处理程序,关于8259A相关信息参考书中P311内容,本质上是一个可编程中断控制器,处理流程如下,init_all负责初始化所有设备及结构体,然后调用idt_init初始化中断相关内容,内部分别调用了pic_init和idt_desc_init实现,其中pic_init初始化8259A,idt_desc_init负责对中断描述符IDT表进行初始化,最后再对IDT表进行加载
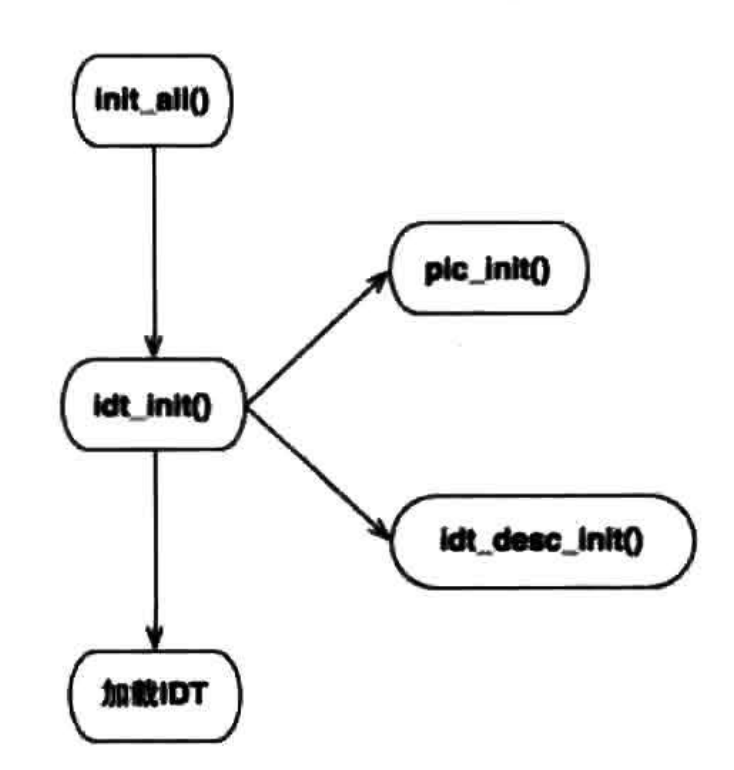
我们需要进行以下几个步骤
- 用汇编语言实现中断处理程序
- 创建中断描述符表IDT,安装中断处理程序
- 用内联汇编实现端口I/O函数(对端口的读写操作)
- 设置8259A
新添加中断后的文件树如下所示,build中是生成后的文件,device中存放的是为了提高中断频率对8253计数器的操作,kernel中新加的interrupt是对中断初始化的主要文件
1 | . |
编译比较麻烦,如下所示
1 | //编译c程序,生成目标文件,这里需要关闭栈保护并指定32位程序 |
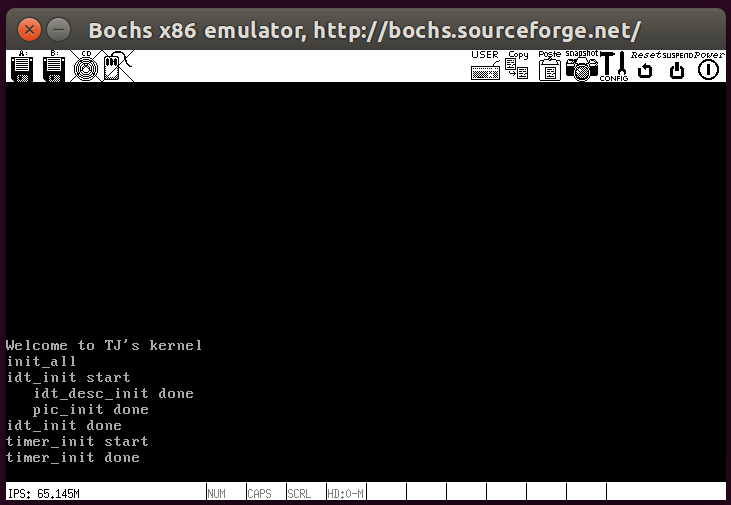
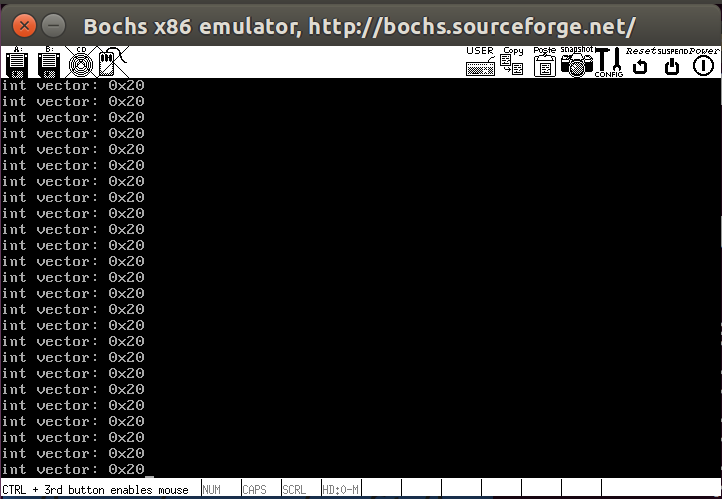
运行结果如下,这里我为了效果演示注释了interrupt.c文件中general_intr_handler函数的最后三行打印中断号的部分,结果如下
取消注释后,效果如下
内存管理系统
在编写内存管理系统之前需要做一些其他的准备工作
Makefile和断言
为了更好的对kernel进行编译,这里使用makefile来操作,makefile具体的知识点就不单独列举了,感兴趣的小伙伴可以自己查阅资料,和作者不同的是这里我是x64的系统,新增了一些编译选项并且把ubantu的终端修改为了bash,具体如下
1 | BUILD_DIR = ./build |
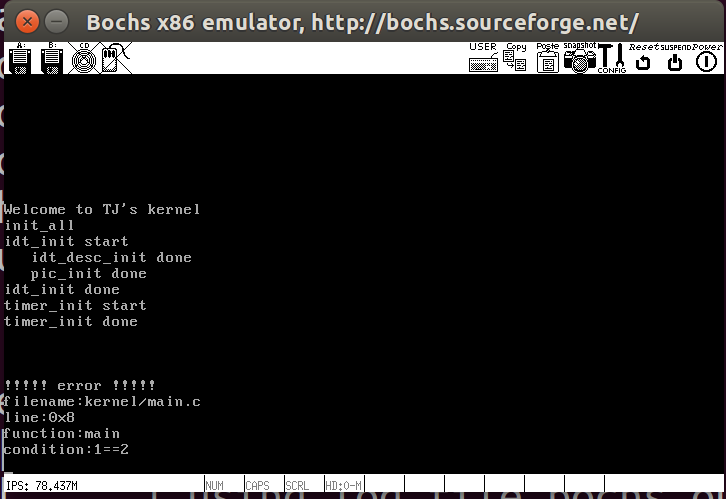
为了调试方便我们新增加了断言(ASSERT),其核心思想是若断言通过则什么都不做,若不通过则用循环实现等待,打印错误信息,具体内容见debug.c和debug.h,在main.c中对其进行测试
1 |
|
主目录下用sudo make all编译之后,测试断言运行效果如下所示
字符串函数实现
在lib目录下用string.c实现对字符串的一些操作函数,比较好理解就不多解释了,代码如下
1 |
|
BITMAP实现
位图用于实现资源管理,相当于一张表,表中为1表示占用,为0表示空闲,之后我们将其用来管理内存,我们在前面的基础之上实现BITMAP,在lib/kernel目录下新增bitmap.h与bitmap.c,代码如下,bitmap结构比较简单,只有两个成员:指针bits和位图的字节长度btmp_bytes_len
1 |
|
下面的一些函数主要是对位图的一些操作函数,还是比较容易看懂的,其中较为核心的函数是bitmap_scan
1 |
|
内存管理
根据之前的铺垫,为了实现内存中用户和内核的区分,我们用位图实现对内存使用情况的记录,我们将物理内存划分为用户内存池和内核内存池,一页为4KB大小。
内核在申请空间的时候,先从内核自己的虚拟地址池中分配好虚拟地址再从内核物理地址池中分配物理内存,最后在内核自己的页表中将这两种地址建立好映射关系,内存就分配完成。
对用户进程来说,它向操作系统申请内存时,操作系统先从用户进程自己的虚拟地址分配虚拟地址,在从用户物理内存池中分配空闲的物理内存,用户物理内存池是被所有用户进程所共享的。最后在用户进程自己的页表中将这两种地址建立好映射关系。
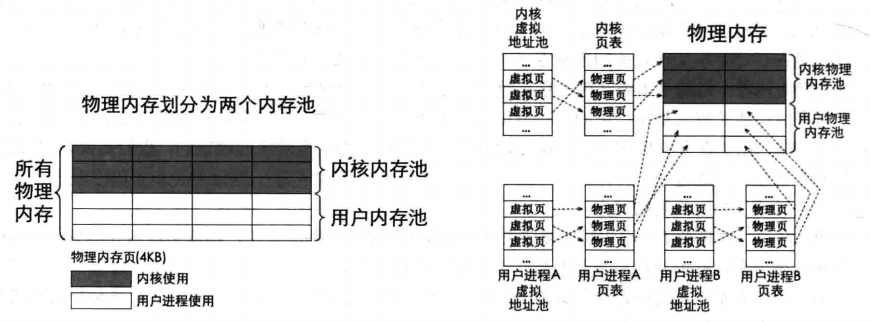
实现在kernel目录下新建memory.c和memory.h,虚拟内存池结构和物理内存池结构如下,物理内存多了一个记录大小的pool_size,因为虚拟地址是连续的4GB空间,相对而言空间非常大,而物理地址是有限的,所以不存在对虚拟地址大小的记录。
1 | struct virtual_addr |
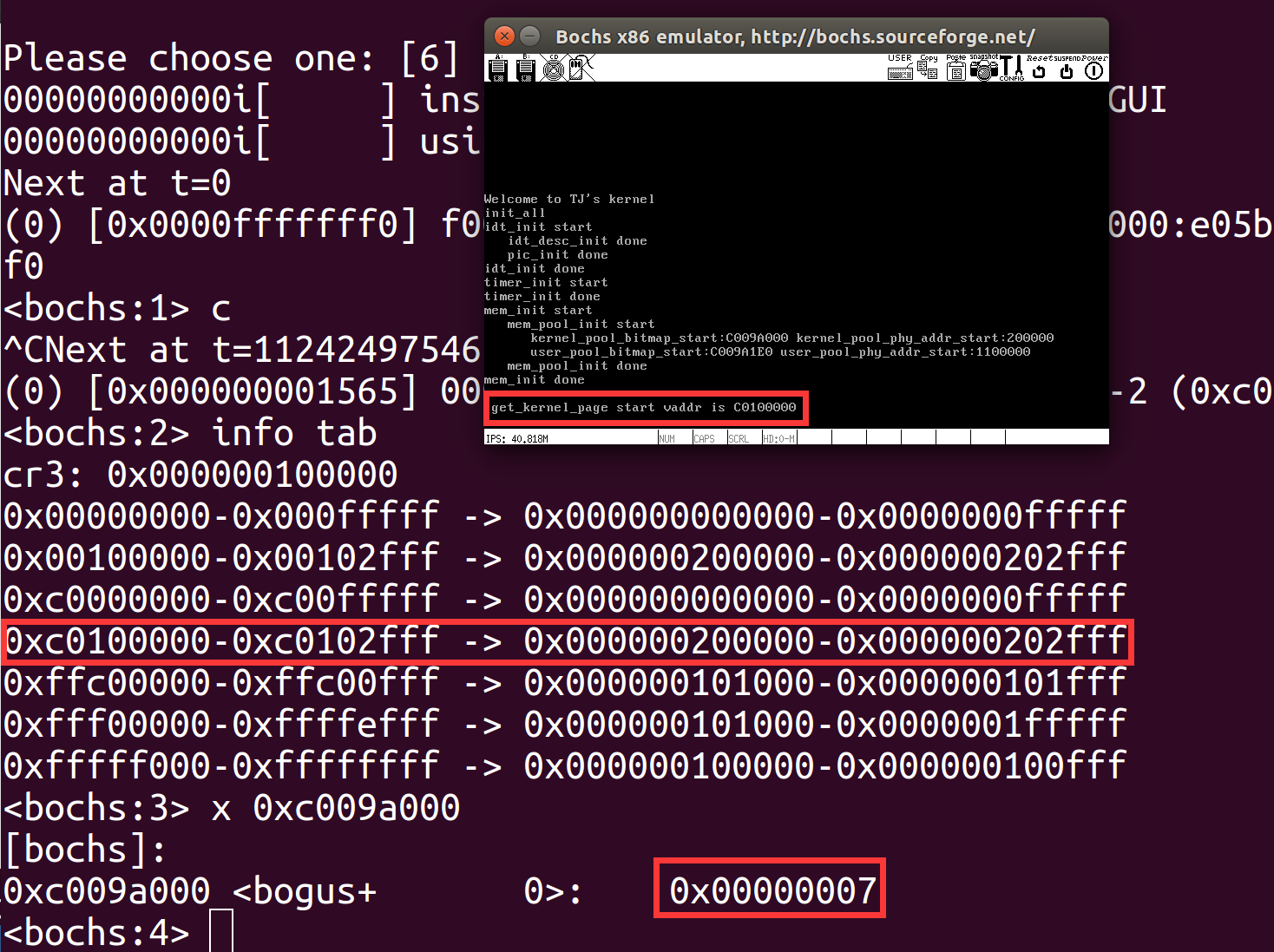
在前面创建页目录和页表的时候,我们将虚拟地址 0xc0000000~0xc00fffff 映射到了物理地址 0x0~0xfffff,0xc0000000 是内核空间的起始虚拟地址,这 1MB 空间做的对等映射。为了看起来使内存连续,所以这里内核堆空间的开始地址从 0xc0100000 开始,在之前的设计中,0xc009f000 为内核主线程的栈顶,0xc009e000 将作为主线程的 PCB 使用,那么在低端1MB的空间中,就只剩下0xc009a000~0xc009dfff这4 * 4KB的空间未使用,所以位图的地址就安排在 0xc009a000 处,这里还剩下四个页框的大小,所能表示的内存大小为512MB
1 |
关键初始化函数如下,主要实现对内核池与用户池在物理内存中的平均分配
1 | // 初始化内存池 |
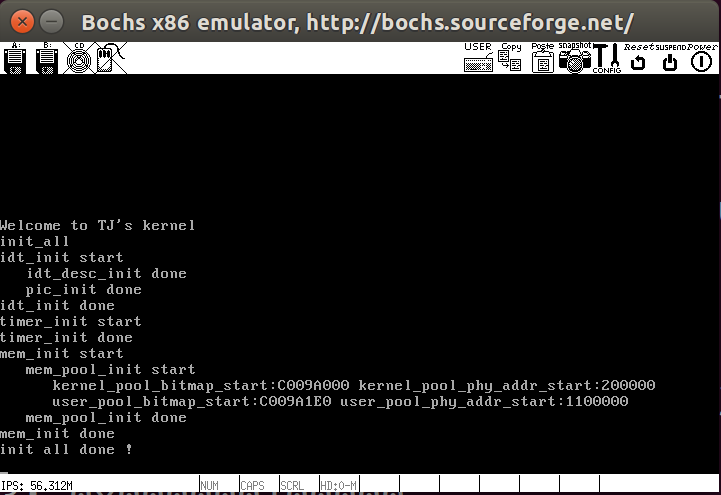
写入makefile文件,编译运行效果如下,我们还没有实现对任意内存申请的函数,这里只是先将内存池进行了初始化,内核物理内存池所用的位图地址在0xc009a000,内存池中第一块物理页地址是0x200000
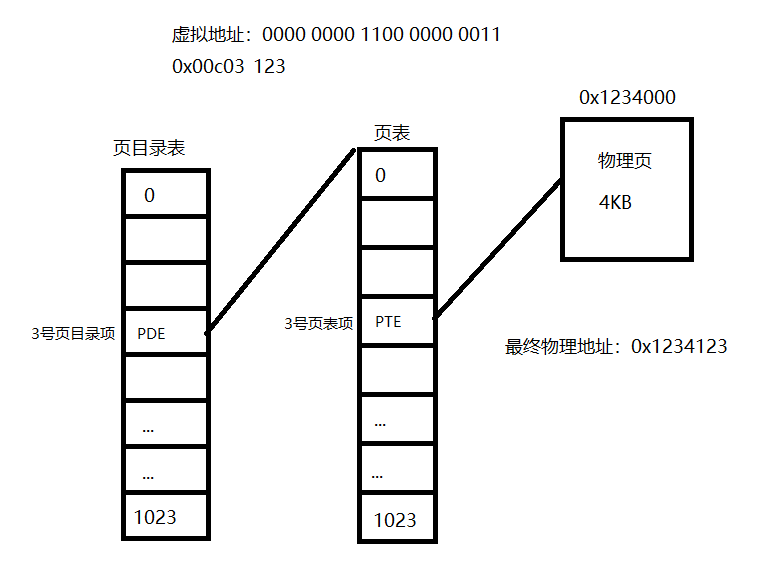
接下来就是实现对内存的分配,首先复习一下32位虚拟地址的转换过程:
- 高 10 位是页目录项 pde 的索引,用于在页目录表中定位 pde ,细节是处理器获取高 10 位后自动将其乘以 4,再加上页目录表的物理地址,这样便得到了 pde 索引对应的 pde 所在的物理地址,然后自动在该物理地址中,即该 pde 中,获取保存的页表物理地址。
- 中间 10 位是页表项 pte 索引,用于在页表中定位 pte 。细节是处理器获取中间 10 位后自动将其乘以 4,再加上第一步中得到的页表的物理地址,这样便得到了 pte 索引对应的 pte 所在的物理地址,然后自动在该物理地址 (该 pte) 中获取保存的普通物理页的物理地址。
- 低 12 位是物理页内的偏移 ,页大小是 4KB, 12 位可寻址的范围正好是 4KB,因此处理器便直接把低 12 位作为第二步中获取的物理页的偏移量,无需乘以 4。用物理页的物理地址加上这低 12 位的和便是这 32 位虚拟地址最终落向的物理地址。
比如访问虚拟地址0x00c03123,拆分步骤如下
1 | 0x00c03123 => 16进制 |
整个过程如下图所示
32位地址在上面转换之后则落向物理地址,内存分配的过程:
- 在虚拟内存池中申请n个虚拟页
- 在物理内存池中分配物理页
- 在页表中添加虚拟地址与物理地址的映射关系
接下来就是一步一步在memory文件中增加函数
在虚拟内存池中申请n个虚拟页
1 | /* 在pf表示的虚拟内存池中申请pg_cnt个虚拟页, |
在物理内存池中分配物理页
这个函数比较关键,主要是对位图的扫描和记录,然后根据位图索引返回分配的物理地址
1 | // 在m_pool指向的物理内存池中分配一个物理页 |
在页表中添加虚拟地址与物理地址的映射关系
再次复习一下32位虚拟地址到物理地址的转换,我们后面实现pde和pte访问就是用的这个原理
- 首先通过高10位的pde索引,找到页表的物理地址
- 其次通过中间10位的pte索引,得到物理页的物理地址
- 最后把低12位作为物理页的页内偏移,加上物理页的物理地址,即为最终的物理地址
下面是通过虚拟地址访问pte和pde的函数
1 | /* 得到虚拟地址vaddr对应的pte指针*/ |
在m_pool处申请物理页的函数
1 | /* 在m_pool指向的物理内存池中分配1个物理页, |
添加虚拟地址与物理地址的映射函数
1 | /* 页表中添加虚拟地址_vaddr与物理地址_page_phyaddr的映射 */ |
malloc_page函数负责申请虚拟地址并分配物理地址、建立映射,大致步骤如下
- 通过vaddr_get在虚拟内存池中申请虚拟地址
- 通过palloc在物理内存池中申请物理页
- 通过page_table_add将以上两步得到的结果在页表中映射
1 | /* 分配pg_cnt个页空间,成功则返回起始虚拟地址,失败时返回NULL */ |
最后一个函数负责在物理内存池中申请pg_cnt页内存
1 | /* 从内核物理内存池中申请pg_cnt页内存,成功则返回其虚拟地址,失败则返回NULL */ |
最后我们在main.c中添加测试代码,申请三个页并打印其虚拟地址
1 |
|
运行效果如下,期中最上面的红框表示虚拟地址起始地址,对照第二个红框的对应关系,第三个红框中为7是因为我们申请了三个页,第三位都为1,位图的变化和预期相符合。